
07 케라스 신경망 모델 활용법
신경망 모델 구성법 1: Sequential 모델 활용
Sequential모델은 층으로 스택을 쌓아 만든 모델이며 가장 단순함- 한 종류의 입력값과 한 종류의 출력값만 사용 가능
- 순전파: 지정된 층의 순서대로 적용
1
2
3
4
5
6
7
from tensorflow import keras
from tensorflow.keras import layers
model = keras.Sequential([
layers.Dense(64, activation="relu"),
layers.Dense(10, activation="softmax")
])
Sequential 모델 층 추가
1
2
3
model = keras.Sequential()
model.add(layers.Dense(64, activation="relu"))
model.add(layers.Dense(10, activation="softmax"))
신경망 모델의 가중치 확인
- 모델 선언 후 바로 가중치와 편향 확인 불가
1
2
3
4
5
>>> model.weights
...
ValueError: Weights for model sequential_1 have not yet been created.
Weights are created when the Model is first called on inputs or
build() is called with an input_shape.
모델의 build() 메서드
-
모델의 빌드 메서드는 각 층별
build()메서드를 차례대로 호출한다.1
>>> model.build(input_shape=(None, 3))
1 2
>>> len(model.weights) 4
-
층별
build()메서드1 2 3 4 5 6
def build(self, input_shape): input_dim = input_shape[-1] # 입력 샘플의 특성 수 self.W = self.add_weight(shape=(input_dim, self.units), initializer="random_normal") self.b = self.add_weight(shape=(self.units,), initializer="zeros")
- 1층의 가중치 행렬(2차원 텐서) 모양: (3, 64)
- 입력값 특성: 3개
- 출력값 특성: 64개
1 2
>>> model.weights[0].shape # 가중치 행렬 TensorShape([3, 64])
- 1층의 편향 벡터(1차원 텐서) 모양: (64,)
- 출력값 특성: 64개
1 2
>>> model.weights[1].shape # 편향 벡터 TensorShape([64])
- 2층의 가중치 행렬(2차원 텐서): (64, 10)
- 입력값 특성: 64개
- 출력값 특성: 10개
1 2
>>> model.weights[2].shape # 가중치 행렬 TensorShape([64, 10])
- 2층의 편향 벡터(1차원 텐서) 모양: (10,)
- 출력값 특성: 10개
1 2
>>> model.weights[3].shape # 편향 벡터 TensorShape([10])
summary() 메서드
- 완성된 신경망 모델의 층의 구조와 각 층의 출력값의 모양 정보를 확인가능
1
2
3
4
5
6
7
8
9
10
11
12
13
>>> model.summary()
Model: "sequential_1"
_________________________________________________________________
Layer (type) Output Shape Param #
=================================================================
dense_2 (Dense) (None, 64) 256
_________________________________________________________________
dense_3 (Dense) (None, 10) 650
=================================================================
Total params: 906
Trainable params: 906
Non-trainable params: 0
_________________________________________________________________
파라미터: 가중치, 편향 벡터를 가지고 있음
\[Param = 편향 벡터 + 가중치 행렬 \\ Param = 3 * 64 + 64 = 256\]Input() 함수
1
2
3
model = keras.Sequential()
model.add(keras.Input(shape=(3,)))
model.add(layers.Dense(64, activation="relu"))
1
2
3
4
5
6
7
8
9
10
11
>>> model.summary()
Model: "sequential_2"
_________________________________________________________________
Layer (type) Output Shape Param #
=================================================================
dense_4 (Dense) (None, 64) 256
=================================================================
Total params: 256
Trainable params: 256
Non-trainable params: 0
_________________________________________________________________
층을 추가할 때 마다 모델의 구조를 확인할 수 있다.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
>>> model.add(layers.Dense(10, activation="softmax"))
>>> model.summary()
Model: "sequential_2"
_________________________________________________________________
Layer (type) Output Shape Param #
=================================================================
dense_4 (Dense) (None, 64) 256
_________________________________________________________________
dense_5 (Dense) (None, 10) 650
=================================================================
Total params: 906
Trainable params: 906
Non-trainable params: 0
_________________________________________________________________
신경망 모델 구성법 2: 함수형 API
features = 순전파
처음 inputs은 (None, 3)의 모양의 가상 텐서
features는 inputs을 call해서 (None, 64)의 가상텐서로 바뀜
모델 지정 단계에서 입력층, 출력층을 지정한다.
은닉층은 어차피 출력층에서 사용하기 때문에 지정 필요 X
1
2
3
4
inputs = keras.Input(shape=(3,), name="my_input") # 입력층
features = layers.Dense(64, activation="relu")(inputs) # 은닉층
outputs = layers.Dense(10, activation="softmax")(features) # 출력층
model = keras.Model(inputs=inputs, outputs=outputs) # 모델 지정
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
>>> model.summary()
Model: "functional_1"
_________________________________________________________________
Layer (type) Output Shape Param #
=================================================================
my_input (InputLayer) [(None, 3)] 0
_________________________________________________________________
dense_6 (Dense) (None, 64) 256
_________________________________________________________________
dense_7 (Dense) (None, 10) 650
=================================================================
Total params: 906
Trainable params: 906
Non-trainable params: 0
_________________________________________________________________
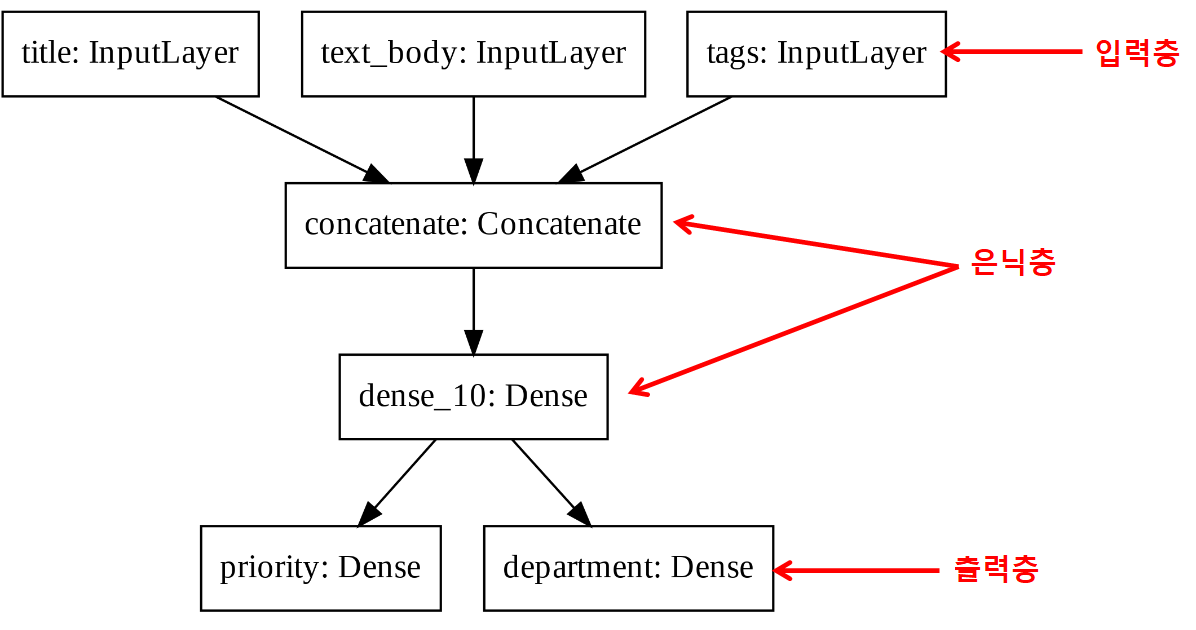
다중 입력, 다중 출력 모델
다중 입력과 다중 출력을 지원하는 모델을 구성하는 방법을 예제를 이용하여 설명한다.
- 입력층: 세 개
- 은닉층: 두 개
- 출력층: 두 개
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
vocabulary_size = 10000 # 사용빈도 1만등 인내 단어 사용
num_tags = 100 # 태그 수
num_departments = 4 # 부서 수
# 입력층: 세 개
title = keras.Input(shape=(vocabulary_size,), name="title")
text_body = keras.Input(shape=(vocabulary_size,), name="text_body")
tags = keras.Input(shape=(num_tags,), name="tags")
# 은닉층
features = layers.Concatenate()([title, text_body, tags]) # shape=(None, 10000+10000+100)
features = layers.Dense(64, activation="relu")(features)
# 출력층: 두 개
priority = layers.Dense(1, activation="sigmoid", name="priority")(features)
department = layers.Dense(
num_departments, activation="softmax", name="department")(features)
# 모델 빌드: 입력값으로 구성된 입력값 리스트와 출력값으로 구성된 출력값 리스트 사용
model = keras.Model(inputs=[title, text_body, tags], outputs=[priority, department])
모델 컴파일
출력값이 2개로 지정했기 때문에 손실 함수, 평가지표도 2개를 지정해야 함.
1
2
3
model.compile(optimizer="adam",
loss=["mean_squared_error", "categorical_crossentropy"],
metrics=[["mean_absolute_error", "mean_squared_error"], ["accuracy", "AUC", "Precision"]])
모델 훈련
1
2
3
model.fit([title_data, text_body_data, tags_data],
[priority_data, department_data]
epochs=10)
모델 평가
1
2
model.evaluate([title_data, text_body_data, tags_data],
[priority_data, department_data])
모델 활용
1
priority_preds, department_preds = model.predict([title_data, text_body_data, tags_data])
-
우선 순위 예측값: 0과 1사이의 확률값
1 2 3 4 5 6 7 8
>>> priority_preds array([[0.], [0.], [0.], ..., [0.], [0.], [0.]], dtype=float32)
-
처리 부서 예측값: 각 부서별 적정도를 가리키는 확률값
1 2 3 4 5 6 7 8 9
>>> department_preds array([[1.26754885e-05, 3.67883259e-11, 2.38737906e-03, 9.97599900e-01], [5.86307794e-03, 4.93278662e-09, 6.00390911e-01, 3.93745989e-01], [1.56256149e-03, 3.38436678e-07, 2.20820252e-02, 9.76355135e-01], ..., [2.97836447e-03, 6.37571304e-07, 4.77804057e-03, 9.92242992e-01], [2.41168109e-05, 3.63892028e-10, 3.09850991e-01, 6.90124929e-01], [9.11577154e-05, 7.13576198e-10, 7.34233633e-02, 9.26485479e-01]], dtype=float32)
각각의 요구사항을 처리해야 하는 부서는
argmax()메서드로 확인된다.1 2
>>> department_preds.argmax() array([3, 2, 3, ..., 3, 3, 3])
사전 객체 활용
1
2
3
4
5
6
7
8
9
10
11
12
13
model.compile(optimizer="adam",
loss={"priority": "mean_squared_error", "department": "categorical_crossentropy"},
metrics={"priority": ["mean_absolute_error", "mean_squared_error"], "department": ["accuracy", "AUC", "Precision"]})
model.fit({"title": title_data, "text_body": text_body_data, "tags": tags_data},
{"priority": priority_data, "department": department_data},
epochs=1)
model.evaluate({"title": title_data, "text_body": text_body_data, "tags": tags_data},
{"priority": priority_data, "department": department_data})
priority_preds, department_preds = model.predict(
{"title": title_data, "text_body": text_body_data, "tags": tags_data})
신경망 모델 구조 그래프
1
>>> keras.utils.plot_model(model, "ticket_classifier.png")
plot_model() 함수 사용 준비 사항
pydot모듈 설치:pip install pydot- graphviz 프로그램 설치: https://graphviz.gitlab.io/download/
- 구글 코랩에서는 기본으로 지원됨.
1
>>> keras.utils.plot_model(model, "ticket_classifier_with_shape_info.png", show_shapes=True)

신경망 모델 재활용
1
2
3
4
5
6
7
8
>>> model.layers
[<keras.src.engine.input_layer.InputLayer at 0x7fc3a1313fd0>,
<keras.src.engine.input_layer.InputLayer at 0x7fc3a13ce450>,
<keras.src.engine.input_layer.InputLayer at 0x7fc3a13c5990>,
<keras.src.layers.merging.concatenate.Concatenate at 0x7fc3a13e0d50>,
<keras.src.layers.core.dense.Dense at 0x7fc3a13a6310>,
<keras.src.layers.core.dense.Dense at 0x7fc3a12f6850>,
<keras.src.layers.core.dense.Dense at 0x7fc3a13e2f90>]
층별 입력값/출력값 정보
3번 인덱스의 층의 입력값과 출력값의 정보는아래와 같다.
1
2
3
4
5
6
7
>>> model.layers[3].input
[<KerasTensor: shape=(None, 10000) dtype=float32 (created by layer 'title')>,
<KerasTensor: shape=(None, 10000) dtype=float32 (created by layer 'text_body')>,
<KerasTensor: shape=(None, 100) dtype=float32 (created by layer 'tags')>]
>>> model.layers[3].output
<KerasTensor: shape=(None, 20100) dtype=float32 (created by layer 'concatenate')>
출력층을 제외한 층 재활용
기존 모델을 사용해 출력층만 추가하려면 아래와 같다.
1
2
3
4
5
6
7
>>> features = model.layers[4].output
>>> difficulty = layers.Dense(3, activation="softmax", name="difficulty")(features)
new_model = keras.Model(
inputs=[title, text_body, tags],
outputs=[priority, department, difficulty])
기존 모델의 은닉층이 좋아서 재활용함
이후 출력층이 추가되었기 때문에 재 훈련을 해야한다.
1
>>> keras.utils.plot_model(new_model, "updated_ticket_classifier.png", show_shapes=True)

신경망 모델 구성법 3: 서브클래싱
- 클래스를 상속하는 모델 클래스를 직접 선언하여 활용
keras.Model클래스를 상속하는 모델 클래스를 직접 선언__init__()메서드(생성자): 은닉층과 출력층으로 사용될 층 객체 지정call()메서드: 층을 연결하는 과정 지정. 즉, 입력값으부터 출력값을 만들어내는 순전파 과정 묘사.
예제: 고객 요구사항 처리 모델
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
class CustomerTicketModel(keras.Model):
def __init__(self, num_departments): # num_departments: 고객 요구사항 처리 부서 개수
super().__init__()
self.concat_layer = layers.Concatenate() # 은닉층
self.mixing_layer = layers.Dense(64, activation="relu") # 은닉층
self.priority_scorer = layers.Dense(1, activation="sigmoid") # 출력층 1
self.department_classifier = layers.Dense( # 출력층 2
num_departments, activation="softmax")
def call(self, inputs): # inputs: 사전 객체 입력값. 모양은 미정.
title = inputs["title"]
text_body = inputs["text_body"]
tags = inputs["tags"]
features = self.concat_layer([title, text_body, tags]) # 은닉층 연결
features = self.mixing_layer(features)
priority = self.priority_scorer(features) # 출력층 연결
department = self.department_classifier(features)
return priority, department # 두 종류의 출력값 지정
1
>>> model = CustomerTicketModel(num_departments=4)
서브클래싱 기법의 장단점
- 장점
call()함수를 이용하여 층을 임의로 구성할 수 있다.for반복문 등 파이썬 프로그래밍 모든 기법을 적용할 수 있다.
- 단점
- 모델 구성을 전적으로 책임져야 한다.
-
모델 구성 정보가
call()함수 외부로 노출되지 않아서앞서 보았던 그래프 표현을 사용할 수 없다.
모델은 층의 자식 클래스
keras.Model이keras.layers.Layer의 자식 클래스- 모델 클래스:
fit(),evaluate(),predict()메서드를 함께 지원
혼합 신경망 모델 구성법
예제: 서브클래싱 모델을 함수형 모델에 활용하기
1
2
3
4
5
6
7
8
9
10
11
12
13
14
class Classifier(keras.Model):
def __init__(self, num_classes=2):
super().__init__()
if num_classes == 2:
num_units = 1
activation = "sigmoid"
else:
num_units = num_classes
activation = "softmax"
self.dense = layers.Dense(num_units, activation=activation)
def call(self, inputs):
return self.dense(inputs)
1
2
3
4
5
inputs = keras.Input(shape=(3,)) # 입력층
features = layers.Dense(64, activation="relu")(inputs) # 은닉층
outputs = Classifier(num_classes=10)(features) # 출력층
model = keras.Model(inputs=inputs, outputs=outputs)
예제: 함수형 모델을 서브클래싱 모델에 활용하기
1
2
3
inputs = keras.Input(shape=(64,))
outputs = layers.Dense(1, activation="sigmoid")(inputs)
binary_classifier = keras.Model(inputs=inputs, outputs=outputs)
1
2
3
4
5
6
7
8
9
10
class MyModel(keras.Model):
def __init__(self, num_classes=2):
super().__init__()
self.dense = layers.Dense(64, activation="relu")
self.classifier = binary_classifier
def call(self, inputs):
features = self.dense(inputs)
return self.classifier(features)
훈련 평가 방식 지정
훈련 과정 동안 관찰할 수 있는 내용은 일반적으로 다음과 같다.
- 에포크별 손실값
- 에포크별 평가지표
사용자 정의 평가지표
Metric클래스 상속- 아래 세 개의 메서드를 재정의\(_{overriding}\)
update_state()result()reset_state()
예제: RootMeanSquaredError 클래스
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
class RootMeanSquaredError(keras.metrics.Metric):
def __init__(self, name="rmse", kwargs):
super().__init__(name=name, kwargs)
self.mse_sum = self.add_weight(name="mse_sum", initializer="zeros")
self.total_samples = self.add_weight(
name="total_samples", initializer="zeros", dtype="int32")
def update_state(self, y_true, y_pred, sample_weight=None):
y_true = tf.one_hot(y_true, depth=tf.shape(y_pred)[1])
mse = tf.reduce_sum(tf.square(y_true - y_pred))
self.mse_sum.assign_add(mse)
num_samples = tf.shape(y_pred)[0]
self.total_samples.assign_add(num_samples)
def result(self):
return tf.sqrt(self.mse_sum / tf.cast(self.total_samples, tf.float32))
def reset_state(self):
self.mse_sum.assign(0.)
self.total_samples.assign(0)
생성자
Metric클래스 상속, 평가지표 이름 지정, 에포크 별로 계산될 평가지표 계산에 필요한 속성(변수) 초기화name="rmse": 평가지표 이름. 훈련중에 평가지표 구분에 사용됨.mse_sum: (에포크 별) 누적 제곱 오차. 0으로 초기화.total_samples: (에포크 별) 훈련에 사용된 총 데이터 샘플 수. 0으로 초기화.
1
2
3
4
5
def __init__(self, name="rmse", kwargs):
super().__init__(name=name, kwargs)
self.mse_sum = self.add_weight(name="mse_sum", initializer="zeros")
self.total_samples = self.add_weight(
name="total_samples", initializer="zeros", dtype="int32")
에포크 상태 업데이트
update_state: 에포크 내에서 스텝 단위로 지정된 속성 업데이트mse: 입력 배치 단위로 계산된 모든 샘플들에 대한 예측 오차의 제곱의 합.mse_sum업데이트: 새롭게 계산된mse를 기존mse_sum에 더함.num_samples: 배치 크기total_samples업데이트: 새로 훈련된 배치 크기를 기존total_samples에 더함
1
2
3
4
5
6
7
8
9
10
11
12
13
def update_state(self, y_true, y_pred, sample_weight=None):
y_true = tf.one_hot(y_true, depth=tf.shape(y_pred)[1])
mse = tf.reduce_sum(tf.square(y_true - y_pred))
self.mse_sum.assign_add(mse)
num_samples = tf.shape(y_pred)[0]
self.total_samples.assign_add(num_samples)
에포크 단위 평가지표 계산
result: 에포크 별로 평가지표 계산- 여기서는 에포크 별로 평균 제곱근 오차 계산.
mse_sum을total_samlpes으로 나눈 값의 제곱근 계산
1
2
def result(self):
return tf.sqrt(self.mse_sum / tf.cast(self.total_samples, tf.float32))
에포크 상태 초기화
reset_state: 새로운 에포크 훈련이 시작될 때 모든 인스턴스 속성(변수) 초기화- 여기서는
mse_sum과total_samlpes모두 0으로 초기화
1
2
3
def reset_state(self):
self.mse_sum.assign(0.)
self.total_samples.assign(0)
사용자 정의 평가지표 활용
1
2
3
4
model = get_mnist_model()
model.compile(optimizer="rmsprop",
loss="sparse_categorical_crossentropy",
metrics=["accuracy", RootMeanSquaredError()])
1
2
3
model.fit(train_images, train_labels,
epochs=3,
validation_data=(val_images, val_labels
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
Epoch 1/3
1563/1563 [==============================] - 12s 7ms/step - loss: 0.2929 - accuracy: 0.9136 - rmse: 7.1776 - val_loss: 0.1463 - val_accuracy: 0.9576 - val_rmse: 7.3533
Epoch 2/3
1563/1563 [==============================] - 11s 7ms/step - loss: 0.1585 - accuracy: 0.9546 - rmse: 7.3526 - val_loss: 0.1215 - val_accuracy: 0.9650 - val_rmse: 7.3954
Epoch 3/3
1563/1563 [==============================] - 11s 7ms/step - loss: 0.1293 - accuracy: 0.9636 - rmse: 7.3837 - val_loss: 0.1058 - val_accuracy: 0.9711 - val_rmse: 7.4182
313/313 [==============================] - 2s 5ms/step - loss: 0.1003 - accuracy: 0.9731 - rmse: 7.4307
콜백
컴퓨터 프로그래밍에서 콜백\(_{callback}\)은
하나의 프로그램이 실행되는 도중에 추가적으로 다른 API를 호출하는 기능 또는 해당 API를 가리킨다.
호출된 콜백은 자신을 호출한 프로그램과 독립적으로 실행된다.
가장 많이 활용되는 콜백은 다음과 같다.
- 훈련 기록 작성
- 훈련 에포크마다 보여지는 손실값, 평가지표 등 관리
keras.callbacks.CSVLogger클래스 활용.
- 훈련중인 모델의 상태 저장
- 훈련 중 가장 좋은 성능의 모델(의 상태) 저장
keras.callbacks.ModelCheckpoint클래스 활용
- 훈련 조기 종료
- 검증셋에 대한 손실이 더 이상 개선되지 않는 경우 훈련을 종료 시키기
keras.callbacks.EarlyStopping클래스 활용
- 하이퍼 파라미터 조정
- 학습률 동적 변경 지원
keras.callbacks.LearningRateScheduler또는keras.callbacks.ReduceLROnPlateau클래스 활용
예제
콜백은 fit() 함수의 callbacks라는 옵션 인자를 이용하여 지정한다.
예를 들어 아래 코드는 두 종류의 콜백을 지정한다.
EarlyStopping: 검증셋에 대한 정확도가 2 에포크 연속 개선되지 않을 때 훈련 종료ModelCheckpoint: 매 에포크마다 훈련된 모델 상태 저장save_best_only=True: 검증셋에 대한 손실값이 가장 낮은 모델만 저장
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
callbacks_list = [
keras.callbacks.EarlyStopping(
monitor="val_accuracy",
patience=2,
),
keras.callbacks.ModelCheckpoint(
filepath="checkpoint_path",
monitor="val_loss",
save_best_only=True,
)
]
model.compile(optimizer="rmsprop",
loss="sparse_categorical_crossentropy",
metrics=["accuracy"])
model.fit(train_images, train_labels,
epochs=10,
callbacks=callbacks_list,
validation_data=(val_images, val_labels))
사용자 정의 콜백
케라스와 호환되는 콜백 클래스를 정의하려면 keras.callbacks.Callback 클래스를 상속하면 된다.
매 에포크와 매 배치 훈련 단계의 시작과 종료 지점에서
수행해야 할 기능을 정의해야 하며 아래 메서드를 재정의하는 방식으로 이루어진다.
1
2
3
4
5
6
on_epoch_begin(epoch, logs)
on_epoch_end(epoch, logs)
on_batch_begin(batch, logs)
on_batch_end(batch, logs)
on_train_begin(logs)
on_train_end(logs)
각 메서드에 사용되는 인자는 훈련 과정 중에 자동으로 생성된 객체로부터 값을 받아온다.
logs인자: 이전 배치와 에포크의 훈련셋과 검증셋에 대한 손실값, 평가지표 등을 포함한 사전 객체.batch와epoch: 배치와 에포크 정보
다음 LossHistory 콜백 클래스는 배치 훈련이 끝날 때마다 손실값을 저장하고
에포크가 끝날 때마다 배치별 손실값을 그래프로 저장하여 훈련이 종료된 후 시각화하여 보여주도록 한다.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
from matplotlib import pyplot as plt
class LossHistory(keras.callbacks.Callback):
def on_train_begin(self, logs):
self.per_batch_losses = []
def on_batch_end(self, batch, logs):
self.per_batch_losses.append(logs.get("loss"))
def on_epoch_end(self, epoch, logs):
plt.clf()
plt.plot(range(len(self.per_batch_losses)), self.per_batch_losses,
label="Training loss for each batch")
plt.xlabel(f"Batch (epoch {epoch})")
plt.ylabel("Loss")
plt.legend()
plt.savefig(f"plot_at_epoch_{epoch}")
self.per_batch_losses = []
텐서보드
텐서보드\(_{TensorBoard}\)는 모델 훈련 과정을 시각적으로 실시간 관찰할 수 있는 도구를 제공하며
텐서플로우와 함께 설치된다.
- 신경망 모델 구조 시각화
- 손실값, 정확도 등의 변화 시각화
- 가중치, 편향 텐서 등의 변화 히스토그램
- 이미지, 텍스트, 오디오 데이터 시각화
- 기타 다양한 기능 제공

텐서보드는 TensorBoard 콜백 클래스를 활용한다.
log_dir: 텐서보드 서버 실행에 필요한 데이터 저장소 지정
1
2
3
4
5
6
7
8
tensorboard = keras.callbacks.TensorBoard(
log_dir="./tensorboard_log_dir",
)
model.fit(train_images, train_labels,
epochs=10,
validation_data=(val_images, val_labels),
callbacks=[tensorboard])
- 주피터 노트북에서
1
2
%load_ext tensorboard
%tensorboard --logdir ./tensorboard_log_dir
- 터미널에서
1
tensorboard --logdir ./tensorboard_log_dir
softmax 순서 알기
정리
신경망 모델 구성법 1: Sequential 모델 활용
- 층을 순차적으로 쌓아 모델을 만드는 방법
- 단일 입력값과 출력값만 처리 가능
- 각 층은 순서대로 연결되어 순차적으로 데이터가 흘러간다.
- 모델을 생성할 때
Sequential클래스를 사용하며, 층을 순서대로 추가한다.- 모델 생성 시 리스트로 층을 추가
- 생성된 모델에
.add()메서드를 사용해 층을 하나씩 추가
- 모델을 선언한 후에는 모델의 가중치와 편향을 확인할 수 없다. 가중치와 편향을 확인하기 위해서는 모델의
build()메서드를 호출해야 한다. - 모델의
build()메서드는 각 층의build()메서드를 차례대로 호출해 모델의 가중치와 편향을 생성한다. summary()메서드를 사용하면 모델의 층 구조와 각 층의 출력 모양, 파라미터 수 등을 확인 가능하다.Input()함수를 사용하여 입력층을 생성하고, 이를 기반으로 층을 추가할 수 있다. 이를 통해 모델의 구조를 동적으로 확인할 수 있다.- 파라미터 수는 각 층의 가중치와 편향을 모두 합한 값으로,
summary()메서드에서 확인할 수 있다.
신경망 모델 구성법 2: 함수형 API
- 복잡한 모델 구조를 만들 수 있는 방법
- 다중 입력 및 다중 출력을 처리 가능
- 레이어 간의 연결을 유연하게 제어 가능
- 모델을 구성할 때, 먼저
Input함수를 사용하여 입력층을 정의한다. - 다음으로, 입력층을 이용하여 은닉층을 정의한다. 은닉층은 순전파 연산을 수행하고,
layers.Dense와 같은 레이어를 사용하여 은닉층을 생성할 수 있다. 예를 들어,keras.Input(shape=(3,), name="my_input")과 같이 입력층을 정의할 수 있다. - 출력층은 은닉층에서 나온 결과를 가지고, 각 출력에 해당하는 레이어를 정의하여 생성한다.
keras.Model을 사용하여 전체 모델을 구성한다. 입력과 출력을 지정하고, 이를 통해 모델을 정의한다. 예를 들어,model = keras.Model(inputs=inputs, outputs=outputs)와 같이 모델을 정의할 수 있다.- 다중 입력 및 다중 출력 모델을 구성할 때, 각 입력 및 출력에 대한 정보를 입력과 출력 리스트로 지정한다. 또한, 출력값이 여러 개이므로 각 출력에 대한 손실 함수 및 평가 지표도 리스트로 지정해야 한다.
- 모델을 컴파일할 때, 모델의 각 출력에 대한 손실 함수 및 평가 지표도 리스트로 지정해야 한다.
- 모델을 훈련하고 평가할 때, 입력 및 출력 데이터도 리스트로 지정해야 한다.
- 함수형 API를 사용하면 모델의 구조를 그래프 형태로 시각화할 수 있으며,
plot_model함수를 사용하여 그래프를 저장하거나 출력할 수 있다. - 함수형 API를 사용하면 모델의 층을 인덱스를 통해 선택하고 재활용할 수 있습니다. 이를 통해 모델의 일부를 변경하거나 추가할 수 있다.
신경망 모델 구성법 3: 서브클래싱
keras.Model클래스를 상속해 사용자 정의 모델 클래스를 직접 선언하는 방법- 모델을 선언할 때
__init__()메서드에서 은닉층과 출력층으로 사용할 층 객체를 지정 call()메서드를 사용하여 층을 연결하는 과정을 지정하며, 이 메서드에서 입력값부터 출력값을 만들어내는 순전파 과정을 정의- 모델 클래스를 인스턴스화하여 모델을 생성할 수 있으며, 이 모델은
keras.Model의 하위 클래스이므로fit(),evaluate(),predict()등의 메서드를 사용 가능
- 모델을 선언할 때
- 서브클래싱 기법을 사용하면 모델을 완전히 사용자 정의할 수 있으며, 모델 구성 정보가
call()함수 내에 캡슐화되므로 모델의 내부를 노출하지 않습니다. 이는 모델을 더 복잡하게 만들고 파이썬 프로그래밍 기법을 활용할 수 있는 장점을 가집니다. - 그러나 서브클래싱 기법의 단점은 모델 구성을 전적으로 개발자가 책임져야 하며, 모델 구성 정보가
call()함수 외부로 노출되지 않기 때문에 모델 구조를 그래프 형태로 시각화하는 기능을 사용할 수 없다. - 모델은
keras.Model의 하위 클래스로 정의되며, 모델 클래스는 층과 같은 방식으로 취급되므로 함수형 모델과 서브클래싱 모델을 혼합하여 사용할 수 있습니다. 이를 통해 모델의 일부를 함수형으로 정의하고 일부를 서브클래싱으로 정의하여 모델을 구성할 수 있습니다.
혼합 신경망 모델 구성법
- 모델을 구성할 때 서로 다른 방법을 혼합하여 사용 가능
훈련 평가 방식 지정
-
사용자 정의 평가지표
사용자 정의 평가지표를 만들기 위해
keras.metrics.Metric클래스를 상속합니다. 사용자 정의 평가지표 클래스는 아래 세 가지 메서드를 재정의해야 합니다:update_state(): 훈련 중에 호출되며, 손실과 평가지표를 계산하는 데 사용됩니다.result(): 에포크나 배치가 끝난 후 호출되며, 최종 평가지표 값을 반환합니다.reset_state(): 에포크가 끝날 때 호출되며, 내부 상태를 초기화합니다.
예를 들어,
RootMeanSquaredError클래스는 평균 제곱근 오차를 계산하는 사용자 정의 평가지표를 구현한 예제입니다. -
콜백
콜백은 훈련 과정 중에 추가적인 동작을 수행할 수 있도록 하는 기능입니다. 케라스에서 제공하는 콜백 클래스들은 다양한 용도로 사용됩니다. 몇 가지 중요한 콜백은 다음과 같습니다:
keras.callbacks.ModelCheckpoint: 모델의 가중치를 저장하고, 가장 성능이 좋은 모델을 자동으로 선택할 수 있도록 도와줍니다.keras.callbacks.EarlyStopping: 손실이 더 이상 개선되지 않으면 훈련을 중지합니다.keras.callbacks.CSVLogger: 훈련과 검증 지표를 CSV 파일에 로깅합니다.keras.callbacks.LearningRateScheduler: 학습률을 동적으로 조정합니다.
사용자 정의 콜백을 만들려면
keras.callbacks.Callback클래스를 상속하고 필요한 메서드를 재정의합니다. 콜백은 훈련 중 각 에포크 또는 배치의 시작 및 종료 시점에서 동작을 정의할 수 있습니다. 예를 들어,LossHistory콜백은 배치별 손실값을 기록하고 에포크별로 그래프로 저장하는 예제입니다. -
텐서보드
텐서보드(TensorBoard)는 훈련 과정을 시각적으로 모니터링하는 도구입니다. 텐서보드를 사용하기 위해
keras.callbacks.TensorBoard콜백 클래스를 활용합니다. 이 콜백은 훈련 중에 생성된 데이터를 텐서보드에 로깅하고, 시각화 도구를 통해 모델의 성능과 다양한 지표를 실시간으로 확인할 수 있습니다.
댓글남기기