
03 케라스와 텐서플로우
1. 딥러닝 주요 라이브러리
- 텐서플로우
- 케라스
- 파이토치
- JAX
1. 텐서플로우\(_{TensorFlow}\)
- 텐서플로우는 파이썬 기본 머신러닝 플랫폼이며, 머신러닝 모델의 훈련에 필요한 텐서 연산을 지원한다.
- 넘파이Numpy 패키지와 유사하지만 보다 많은 기능을 제공한다.
- 텐서플로우는 또한 단순한 패키지 기능을 넘어서는 머신러닝 플랫폼 역할도 수행한다.
- 파이썬에 기반한 머신러닝 플랫폼
- 머신러닝 모델의 훈련에 필요한 텐서 연산을 지원
- 그레이디언트 자동 계산
- GPU, TPU 등 고성능 병렬 하드웨어 가속기 활용 가능
- 여러 대의 컴퓨터 또는 클라우드 컴퓨팅 서비스 활용 가능
- C++(게임), 자바스크립트(웹브라우저), TFLite(모바일 장치) 등과 호환 가능
- 단순한 패키지 기능을 넘어서는 머신러닝 플랫폼
- TF-Agents: 강화학습 연구 지원
- TFX: 머신러닝 프로젝트 운영 지원
- TensorFlow-Hub: 사전 훈련된 머신러닝 모델 제공
2. 케라스
- 딥러닝 모델 구성 및 훈련에 효율적으로 사용될 수 있는 다양한 수준의 API를 제공하며, 텐서플로우의 프론트엔드 인터페이스 기능을 수행한다.
- 원래 텐서플로우와 독립적으로 개발되었지만 텐서플로우 2.0부터 텐서플로우 라이브러리의 최상위 프레임워크\(_{framework}\)로 포함됐다.

그림 출처: Deep Learning with Python(2판)
3. 딥러닝 주요 라이브러리 약력
- 2007년: 씨아노\(_{Theano}\) 공개. 텐서를 이용한 계산 그래프, 미분 자동화 등을 최초로 지원한 딥러닝 라이브러리.
- 2015년 3월: 케라스 라이브러리 공개. \(_{Theano}\)를 백앤드로 사용하는 고수준 패키지.
- 2015년 11월: 텐서플로우 라이브러리 공개.
- 2016년: 텐서플로우가 케라스의 기본 백엔드로 지정됨.
- 2016년 9월: 페이스북이 개발한 파이토치\(_{PyTorch}\) 공개.
- 2017년: \(_{Theano}\), 텐서플로우, \(_{CNTK}\)(마이크로소프트), \(_{MXNet}\)(아마존)이 케라스의 백엔드로 지원됨. 현재 \(_{Theano}\), \(_{CNTK }\)등은 더 이상 개발되지 않으며, \(_{MXNet}\)은 아마존에서만 주로 사용됨.
- 2018년 3월: \(_{PyTorch}\)와 \(_{Caffe2}\)를 합친 \(_{PyTorch}\)출시(페이스북과 마이크로소프트의 협업)
- 2019년 9월: 텐서플로우 2.0부터 케라스가 텐서플로우의 최상위 프레임워크로 지정됨.
- 2023년 가을: \(_{Keras \ Core}\)가 케라스 3.0으로 출시 예정. 텐서플로우, \(_{PyTorch}\), \(_{JAX}\)의 프론트엔드 기능 지원.
케라스 코어
파이토치 또한 텐서 연산을 지원하는 딥러닝 라이브러리이다.
텐서플로우와 케라스의 조합이 강력하지만 신경망의 보다 섬세한 조정은 약하다는 지적을 많이 받는 반면에 파이토치는 상대적으로 보다 자유롭게 신경망을 구성할 수 있다고 평가된다.
텐서플로우와 케라스의 조합이 여전히 보다 많이 사용되지만 딥러닝 연구에서 파이토치의 활용 또한 점점 늘고 있다.
호도에 대한 논쟁이 지난 몇 년간 있어 왔지만 상대적으로 약해질 것으로 기대된다.
이유는 케라스 3.0부터 텐서플로우뿐만 아니라 파이토치도 케라스의 지원을 받기 때문이다.
4. 딥러닝 개발환경
딥러닝 신경망 모델의 훈련을 위해서 GPU를 활용하면 좋다.
GPU를 사용하지 않으면 모델의 훈련이 느려진다는 단점이 있다.
딥러닝 모델 훈련을 많이 시키려면 NVIDIA 그래픽카드가 장착된 개인용 컴퓨터를 활용하는 것이 좋다.
운영체제는 Ubuntu 또는 윈도우 11을 추천한다.
- 윈도우 11에서 GPU를 지원 텐서플로우 설치: conda를 활용한 gpu 지원 tensorflow 설치 요령 참고
- 우분투에서 GPU 지원하는 텐서플로우 설치: Anaconda와 conda 환경 활용 참고
위 내용들은 전문적이기 보다는 그냥 맛만 보는 정도로 적당하다고 보면 된다.
5. **순수 텐서플로우 사용법 기초**
케라스 없이 텐서플로우만 이용해서 신경망 모델을 지정하고 훈련시킬 수 있다.
하지만 아래에 언급된 개념, 기능, 도구를 모두 직접 구현해야 한다.
- 가중치, 편향 등을 저장할 텐서 지정
- 순전파 실행(덧셈, 행렬 곱,
relu()함수 등 활용) - 역전파 실행
- 층과 모델
- 손실 함수
- 옵티마이저
- 평가지표
- 훈련 루프
2. 텐서플로우 텐서
tf.Tensor자료형- 상수 텐서
- 입출력 데이터 등 변하지 않는 값을 다룰 때 사용.
- 불변 자료형
tf.Variable자료형- 변수 텐서
- 모델의 가중치, 편향 등 항목의 업데이트가 필요할 때 사용되는 텐서.
- 가변 자료형
상수 텐서
-
다양한 방식으로 상수 텐서 생성
1 2 3 4 5 6
>>> x = tf.constant([[1., 2.], [3., 4.]]) >>> print(x) tf.Tensor( [[1. 2.] [3. 4.]], shape=(2, 2), dtype=float32)
1 2 3 4 5
>>> x = tf.ones(shape=(2, 1)) >>> print(x) tf.Tensor( [[1.] [1.]], shape=(2, 1), dtype=float32)
1 2 3 4 5 6
>>> x = tf.zeros(shape=(2, 1)) >>> print(x) tf.Tensor( [[0.] [0.]], shape=(2, 1), dtype=float32)
-
normal()함수: 정규 분포 활용1 2 3 4 5 6 7
>>> x = tf.random.normal(shape=(3, 1), mean=0., stddev=1.) >>> print(x) tf.Tensor( [[-0.5644841 ] [-0.76016265] [ 0.30502525]], shape=(3, 1), dtype=float32)
-
uniform()함수: 균등 분포 활용1 2 3 4 5 6 7
>>> x = tf.random.uniform(shape=(3, 1), minval=0., maxval=1.) >>> print(x) tf.Tensor( [[0.33661604] [0.09824598] [0.32487237]], shape=(3, 1), dtype=float32)
상수 텐서의 수정 불가능성
1
2
3
4
5
6
7
>>> x[0, 0] = 1.0
TypeError Traceback (most recent call last)
<ipython-input-7-242a5d4d3c4a> in <module>
----> 1 x[0, 0] = 1.0
TypeError: 'tensorflow.python.framework.ops.EagerTensor' object does not support item assignment
텐서 항목의 자료형
1
2
3
>>> type(x[0, 0])
tensorflow.python.framework.ops.EagerTensor
변수 텐서
1
2
3
4
5
6
7
>>> v = tf.Variable(initial_value=tf.random.normal(shape=(3, 1)))
>>> print(v)
<tf.Variable 'Variable:0' shape=(3, 1) dtype=float32, numpy=
array([[-1.3837979 ],
[-0.23704937],
[-0.9790895 ]], dtype=float32)>
변수 텐서 교체
1
2
3
4
5
6
>>> v.assign(tf.ones((3, 1)))
<tf.Variable 'UnreadVariable' shape=(3, 1) dtype=float32, numpy=
array([[1.],
[1.],
[1.]], dtype=float32)>
-
대체하는 텐서의 모양(shape)이 기존 텐서의 모양과 동일해야 함
1 2 3 4 5 6 7 8 9 10 11 12 13 14
>>> v.assign(tf.ones((3, 2))) ValueError Traceback (most recent call last) <ipython-input-13-e381ab0c94e6> in <module> ----> 1 v.assign(tf.ones((3, 2))) ~\\anaconda3\\lib\\site-packages\\tensorflow\\python\\ops\\resource_variable_ops.py in assign(self, value, use_locking, name, read_value) 886 else: 887 tensor_name = " " + str(self.name) --> 888 raise ValueError( 889 ("Cannot assign to variable%s due to variable shape %s and value " 890 "shape %s are incompatible") % ValueError: Cannot assign to variable Variable:0 due to variable shape (3, 1) and value shape (3, 2) are incompatible
변수 텐서 항목 수정
1
2
3
4
5
6
>>> v[0, 0].assign(3.)
<tf.Variable 'UnreadVariable' shape=(3, 1) dtype=float32, numpy=
array([[3.],
[1.],
[1.]], dtype=float32)>
assign_add()와assign_sub()assign_sub()메서드:=연산자-
assign_add()메서드:+=연산자1 2 3 4 5 6
>>> v.assign_sub(tf.ones((3, 1))) <tf.Variable 'UnreadVariable' shape=(3, 1) dtype=float32, numpy= array([[2.], [0.], [0.]], dtype=float32)>
3. 텐서플로우 활용법 기초
그레이디언트 테이프
\[f(x) = x^2 \quad \Longrightarrow \quad \nabla f(x) = \frac{df(x)}{dx} = 2x\]1
2
3
4
5
6
7
8
9
10
>>> input_var = tf.Variable(initial_value=3.)
>>> with tf.GradientTape() as tape:
... result = tf.square(input_var)
>>> gradient = tape.gradient(result, input_var)
>>> print(gradient)
tf.Tensor(6.0, shape=(), dtype=float32)
예제: 선형 이진 분류기
1단계: 데이터셋 생성
1
2
3
4
5
6
7
8
9
num_samples_per_class = 1000
# 음성 데이터셋
negative_samples = np.random.multivariate_normal(
mean=[0, 3], cov=[[1, 0.5],[0.5, 1]], size=num_samples_per_class)
# 양성 데이터셋
positive_samples = np.random.multivariate_normal(
mean=[3, 0], cov=[[1, 0.5],[0.5, 1]], size=num_samples_per_class)
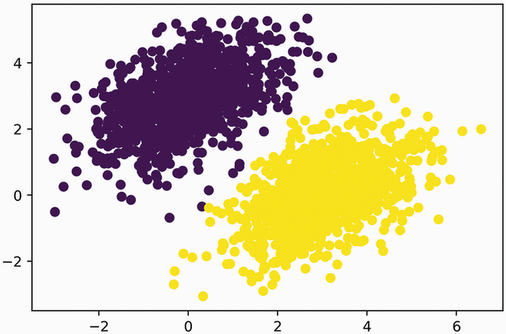
그림 출처: Deep Learning with Python(2판)
음성 데이터셋과 양성 데이터셋을 합쳐서 훈련셋을 생성한다.
negative_sample: (1000, 2) 모양의 텐서positive_sample: (1000, 2) 모양의 텐서inputs = np.vstack(negative_sample, positive_sample): (2000, 2) 모양의 텐서negative_sample데이터셋이 0번부터 999번까지 인덱스.positive_sample데이터셋이 1000번부터 1999번까지 인덱스.
1
inputs = np.vstack((negative_samples, positive_samples)).astype(np.float32)
음성 샘플의 레이블은 0, 양성 샘플의 레이블은 1로 지정한다.
-
np.zeros((num_samples_per_class, 1), dtype="float32"): (1000, 1) 모양의 어레이. 0으로 채워짐.0번부터 999번 인덱스까지의 모든 음성 데이터의 타깃은 0임.
-
np.ones((num_samples_per_class, 1), dtype="float32"): (1000, 1) 모양의 어레이. 1로 채워짐.999번부터 1999번 인덱스까지의 모든 양성 데이터의 타깃은 1임.
-
targets: (2000, 1) 모양의 어레이.
1
2
targets = np.vstack((np.zeros((num_samples_per_class, 1), dtype="float32"),
np.ones((num_samples_per_class, 1), dtype="float32")))
2단계: 선형 회귀 모델 훈련에 필요한 가중치 변수 텐서와 편향 변수 텐서 생성
선형 분류기 모델의 예측값 계산은 다음과 같이 아핀 변환으로 이뤄진다.
1
2
3
4
5
6
7
8
9
10
11
inputs @ W + b
input_dim = 2 # 입력 샘플의 특성이 2개
output_dim = 1 # 각각의 입력 샘플에 대해 하나의 부동소수점을 예측값으로 계산
# 가중치: (2, 1) 모양의 가중치 행렬을 균등분포를 이용한 무작위 초기화
W = tf.Variable(initial_value=tf.random.uniform(shape=(input_dim, output_dim)))
# 편향: (1,) 모양의 벡터를 0으로 초기화
b = tf.Variable(initial_value=tf.zeros(shape=(output_dim,)))
inputs: (2000, 2) 모양의 입력 데이터셋 행렬W: (2, 1) 모양의 가중치 행렬inputs @ W: (2000, 1) 모양의 행렬b: (1,) 모양의 편향 벡터inputs @ W + b: (2000, 1) 모양의 출력값 행렬. 즉, 2000 개의 입력 데이터 각각에 대해 하나의 값의 계산됨.
3단계: 모델 선언(포워드 패스)
1
2
3
4
5
6
7
8
9
10
def dense(inputs, W, b, activation=None):
outputs = tf.matmul(inputs, W) + b
if activation != None:
return activation(outputs)
else:
return outputs
def model(inputs):
outputs = dense(inputs, W, b)
return outputs
하나의 층만 사용
여러 층을 사용하고 싶다면 dense를 추가하고 outputs를 dense의 개수에 맞게 설정하면 됨
4단계: 손실 함수 지정
\[MSE = \frac{1}{m_b}\sum (y - \hat y)^2\]- \(m_b\): 배치 크기
- \(y\): 라벨 0, 1
- \(\hat y\): 예측값
1
2
3
def square_loss(targets, predictions):
per_sample_losses = tf.square(targets - predictions)
return tf.reduce_mean(per_sample_losses)
5단계: 훈련 스텝(역전파) 지정
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
def training_step(inputs, targets):
"""
- inputs: 입력 데이터 배치
- targets: 타깃 배치
"""
# 손실 함수의 그레이디언트 계산 준비
with tf.GradientTape() as tape:
predictions = model(inputs)
loss = square_loss(targets, predictions)
# 가중치와 편향에 대한 손실 함수의 그레이디언트 계산
grad_loss_wrt_W, grad_loss_wrt_b = tape.gradient(loss, [W, b])
# 가중치 행렬과 편향 벡터 업데이트
W.assign_sub(grad_loss_wrt_W * learning_rate) # 가중치 행렬 업데이트
b.assign_sub(grad_loss_wrt_b * learning_rate) # 편향 업데이트
return loss
6단계: 훈련 루프 지정
- 반복해서 훈련한 내용을 출력
-
설명을 간단하게 하기 위해 전체 데이터셋을 하나의 배치로 사용하는 훈련 구현
1 2 3
for step in range(40): loss = training_step(inputs, targets) print(f"Loss at step {step}: {loss:.4f}")
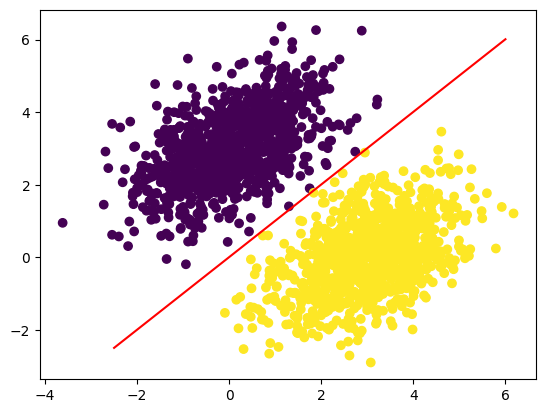
7단계: 결정경계
결정경계를 직선으로 그리려면 아래 일차 함수를 이용한다.
1
y = - W[0] / W[1] * x + (0.5 - b) / W[1]
이유는 아래 식으로 계산되는 모델의 예측값이
0.5보다 큰지 여부에 따라 양성/음성이 판단되기 때문이다.
1
W[0]*x + W[1]*y + b
4. 케라스 신경망 모델의 핵심 API
- 신경망 모델은 층으로 구성됨
- 모델에 사용되는 층의 종류와 층을 쌓는 방식에 따라 모델이 처리할 수 있는 데이터와 훈련 방식이 달라짐
- 케라스 라이브러리가 층을 구성하고 훈련 방식을 관장하는 다양한 API 제공
층
-
입력 데이터를 지정된 방식에 따라 다른 모양의 데이터로 변환하는
포워드 패스\(_{forward \ pass}\)를 담당
-
데이터 변환에 사용되는 가중치\(_{weight}\)와 편향\(_{bias}\) 저장
층의 종류
- 층의 종류에 따라 입력 배치 데이터셋 텐서의 모양이 달라진다.
Dense클래스- 밀집층 생성
(배치 크기, 특성 수)모양의 2D 텐서로 입력된 데이터셋 처리.
LSTM또는Conv1D클래스- 순차 데이터와 시계열 데이터 분석에 사용되는 순환층 생성
(배치 크기, 타임스텝 수, 특성 수)모양의 3D 텐서로 입력된 순차 데이터셋 처리.
Conv2D클래스- 합성곱 신경망(CNN) 구성에 사용되는 합성곱층 생성
(배치 크기, 가로, 세로, 채널 수)모양의 4D 텐서로 제공된 이미지 데이터셋 처리.
**tf.keras.layers.Layer 클래스**
- Layer: 층의 기본 클래스, 상속
- 케라스의 모든 층 클래스는
tf.keras.layers.Layer클래스를 상속한다. - 상속되는
__call__()매직 메서드:- 가중치와 편향 텐서 초기화: 가중치와 편향이 이미 생성되어 있다면 새로 생성하지 않고 그대로 사용
- 입력 데이터셋을 출력 데이터셋으로 변환하는 포워드 패스를 수행
-
**__call__()메서드가 하는 일 (★중요함★)**1 2 3 4 5
def __call__(self, inputs): if not self.built: self.build(inputs.shape) self.built = True return self.call(inputs)
built:False라면build를 실행build: 가중치와 편향을 초기화 해줌self.call: 순전파 연산에 대한 결과값을 반환- 직접 층\(_{Dense}\)을 선언하려면
build와call을 직접 정의해야 함
직접 Dense 클래스 구현하기 (★중요함★)
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
from tensorflow import keras
class SimpleDense(keras.layers.Layer):
def __init__(self, units, activation=None):
super().__init__()
self.units = units # 유닛 개수 지정
self.activation = activation # 활성화 함수 지정
# 가중치와 편향 초기화
def build(self, input_shape):
input_dim = input_shape[-1] # 입력 샘플의 특성 수
self.W = self.add_weight(shape=(input_dim, self.units),
initializer="random_normal")
self.b = self.add_weight(shape=(self.units,),
initializer="zeros")
# 데이터 변환(포워드 패스)
def call(self, inputs):
y = tf.matmul(inputs, self.W) + self.b
if self.activation is not None:
y = self.activation(y)
return y
예제:
**SimpleDense층의 데이터 변환**
- 유닛 수: 512개
활성화 함수:
relu
- 128: 배치 크기
784: MNIST 데이터셋의 손글씨 이미지 한 장의 특성 수(
28 * 28 = 128)
층의 데이터 변환 결과
내부적으로는
__call__()메서드가 호출됨:
- 가중치 텐서와 와 편향 텐서가 생성되지 않은 경우
- (784, 512) 모양의 가중치 텐서 W 생성 및 무작위 초기화. 782는 입력 샘플의 특성 수, 512는 층의 유닛 수.
(512, ) 모양의 편향 텐서 b 생성 및 0으로 초기화. 512는 층의 유닛 수.
- 포워드 패스: 생성된 가중치와 편향을 이용하여 출력값 계산.
- 가중치 텐서와 와 편향 텐서가 생성되어 있는 경우. 즉 훈련이 반복되는 경우.
포워드 패스: 역전파로 업데이트된 가중치와 편향을 이용하여 출력값 계산.
모델
- 케라스의 모든 모델 클래스는 tf.keras.Model 클래스를 상속
-
예제: 아래 모델 직접 구현하기
1 2 3 4
model = keras.Sequential([ layers.Dense(512, activation="relu"), layers.Dense(10, activation="softmax") ])
1 2 3 4 5 6 7 8 9 10 11
class MySequential(keras.Model): def __init__(self, list_layers): # 층들의 리스트 지정 super().__init__() self.list_layers = list_layers # 포워드 패스: 층과 층을 연결하는 방식으로 구 def call(self, inputs): outputs = inputs for layer in self.list_layers: outputs = layer(outputs) return outputs
1 2 3 4
layer_1 = SimpleDense(units=512, activation=tf.nn.relu) # 첫째 밀집층 layer_2 = SimpleDense(units=10, activation=tf.nn.softmax) # 둘째 밀집층 model = MySequential([layer_1, layer_2])
keras.layers.Dense 층을 이용한다면 다음과 같이 활성화 함수를 문자열로 지정할 수 있다.
1
2
3
4
layer_1 = Dense(units=512, activation='relu') # 첫째 밀집층
layer_2 = Dense(units=10, activation='softmax') # 둘째 밀집층
model = MySequential([layer_1, layer_2])
모델을 하나의 층으로 활용하기
- 기존에 정의된 모델을 다른 모델을 구성할 때 하나의 층으로 활용할 수도 있다.
- 이런 이유로
tf.keras.Model클래스는tf.keras.layers.Layer클래스를 상속하도록 설계되어 있다.
모델의 학습과정과 층의 구성
- 모델의 학습과정은 전적으로 층의 구성방식에 의존한다.
- 층의 구성 방식은 주어진 데이터셋과 모델이 해결해야 하는 문제에 따라 달라진다.
- 층을 구성할 때 특별히 정해진 규칙은 없다. (단, 관행은 존재)
- 문제 유형에 따른 권장 모델이 다양하게 개발되어 있다.
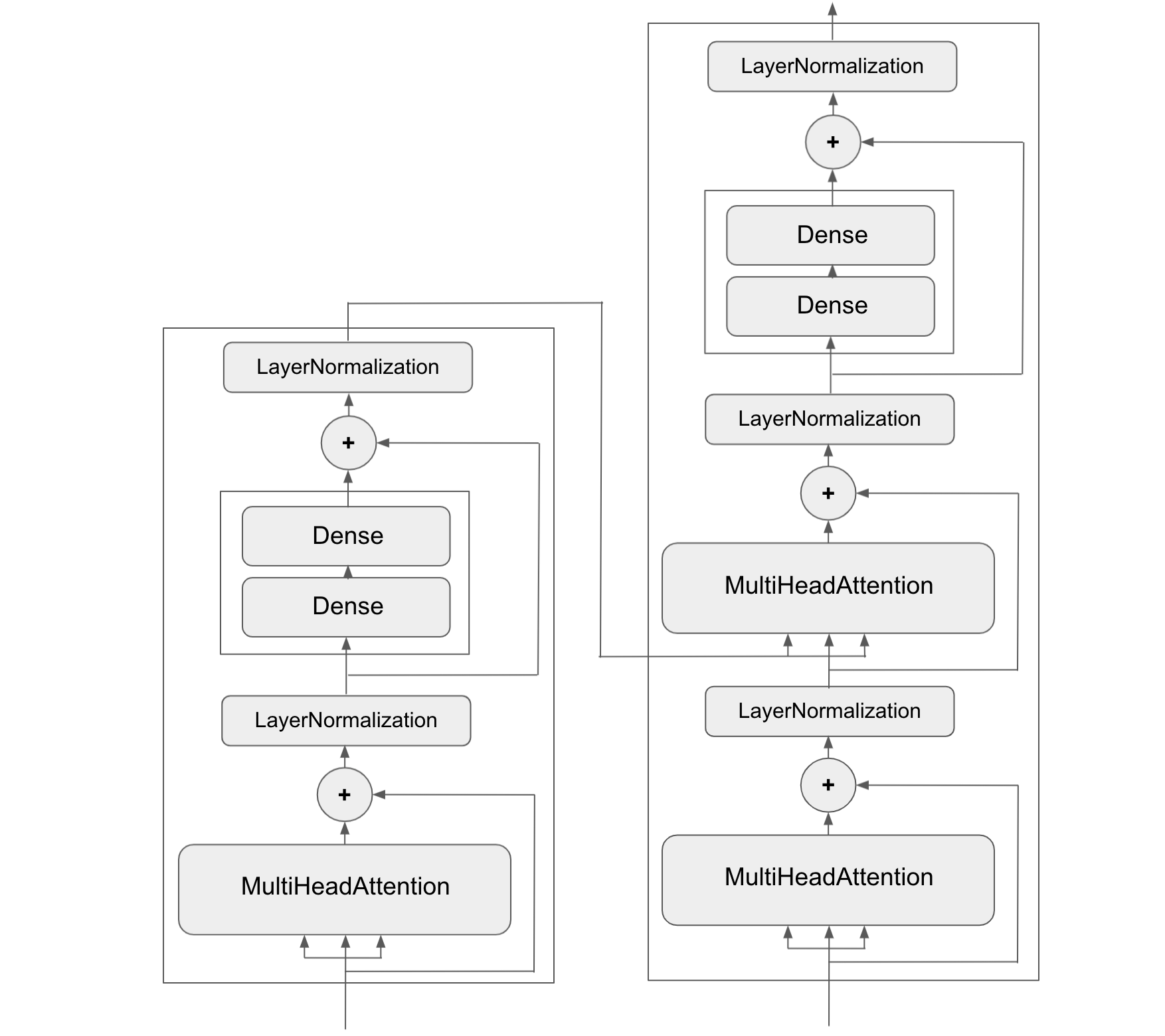
예제: 자연어 처리에 사용되는 트랜스포머 모델
모델 컴파일
1
2
3
model.compile(optimizer="rmsprop",
loss="sparse_categorical_crossentropy",
metrics=["accuracy"])
| 문자열 | 파이썬 객체 |
|---|---|
| rmsprop | keras.optimizers.RMSprop() |
| mean_squared_error | keras.losses.MeanSquaredError() |
| accuracy | keras.metrics.BinaryAccuracy() |
1
2
3
model.compile(optimizer=keras.optimizers.RMSprop(),
loss=keras.losses.MeanSquaredError(),
metrics=[keras.metrics.BinaryAccuracy()])
다음 두 가지의 경우엔 문자열 대신 해당 객체를 지정해야 한다.
- 예를 들어, 기본값과 다른 학습률(
learning_rate)을 사용하는 옵티마이저를 지정하는 경우 - 사용자가 직접 정의한 객체를 사용하는 경우
아래 코드는 직접 객체를 지정하는 방식으로 모델을 컴파일하는 형식을 보여준다.
1
2
3
model.compile(optimizer=keras.optimizers.RMSprop(learning_rate=1e-4),
loss=사용자정의손실함수객체,
metrics=[사용자정의평가지표_1, 사용자정의평가지표_2])
일반적으로 가장 많이 사용되는 옵티마이저, 손실함수, 평가지표는 다음과 같으며
앞으로 다양한 예제를 통해 적절한 옵티마이저, 손실함수, 평가지표를 선택하는 방법을 살펴볼 것이다.
옵티마이저 종류
- SGD (with or without momentum)
- RMSprop
- Adam
- Adagrad
손실 함수 종류
- CategoricalCrossentropy
- SparseCategoricalCrossentropy
- BinaryCrossentropy
- MeanSquaredError
- KLDivergence
- CosineSimilarity
평가지표 종류
- CategoricalAccuracy
- SparseCategoricalAccuracy
- BinaryAccuracy
- AUC
- Precision
- Recall
훈련 루프
모델을 컴파일한 다음에 fit() 메서드를 호출하면
모델은 스텝 단위로 반복되는 훈련 루프\(_{training \ loop}\)가 작동한다.
지정된 에포크 만큼 또는 학습이 충분히 이루어졌다는 평가가 내려질 때까지
훈련을 반복한다.
지도학습 모델 훈련
모델을 훈련시키려면 fit() 메서드를 적절한 인자들과 함께 호출해야 한다.
1
2
3
4
5
6
training_history = model.fit(
inputs,
targets,
epochs=5,
batch_size=128
)
- (지도 학습 모델의 경우) 훈련셋\(_{inputs}\)과 타깃셋\(_{targets}\): 보통 넘파이 어레이 또는 텐서플로우의
Dataset객체 사용 - 에포크\(_{epochs}\): 전체 훈련 세트를 몇 번 훈련할 지 지정
- 배치 크기\(_{batch\_size}\): 하나의 스텝 과정에서 사용되는 데이터 묶음(배치)의 크기
History 객체: 훈련 결과
모델의 훈련 결과로 History 객체가 반환된다.
예를 들어 History 객체의 history 속성은 에포크별로 계산된 손실값과 평가지표값을
사전 자료형으로 가리킨다.
1
2
3
4
5
6
7
8
9
10
11
>>> training_history.history
{'loss': [9.07500171661377,
8.722702980041504,
8.423994064331055,
8.137178421020508,
7.8575215339660645],
'binary_accuracy': [0.07800000160932541,
0.07999999821186066,
0.08049999922513962,
0.08449999988079071,
0.0860000029206276]}
검증 데이터 활용
머신러닝 모델 훈련의 목표는 훈련셋에 대한 높은 성능이 아니라
훈련에서 보지 못한 새로운 데이터에 대한 정확한 예측이다.
훈련 중에 또는 훈련이 끝난 후에 모델이 새로운 데이터에 대해 정확한 예측을 하는지
여부를 판단하도록 할 수 있다.
이를 위해 전체 데이터셋을 훈련셋과 검증셋\(_{validation \ dataset}\)으로 구분한다.
훈련셋과 검증셋의 비율은 보통 8대2 또는 7대3 정도로 하지만
훈련셋이 매우 크다면 검증셋의 비율을 보다 적게 잡을 수 있다.
훈련셋 자체가 매우 작은 경우엔 검증셋을 따로 분리하기 보다는 K-겹 교차 검증 등을 사용해야 한다.
훈련셋과 검증셋이 서로 겹치지 않도록 주의해야 한다.
그렇지 않으면 훈련 중에 모델이 검증셋에 포함된 데이터를 학습하기에
정확환 모델 평가를 할 수 없게 된다.
훈련 중 모델 검증
아래 코드는 미리 지정된 검증셋 val_inputs와 검증 타깃값 val_targets를
validation_data의 키워드 인자로 지정해서
모델 훈련 중에 에포크 단위로 측정하도록 한다.
1
2
3
4
5
6
7
model.fit(
training_inputs,
training_targets,
epochs=5,
batch_size=16,
validation_data=(val_inputs, val_targets)
)
훈련 후 모델 검증
훈련이 끝난 모델의 성능 검증하려면 evaluate() 메서드를 이용한다.
배치 크기(batch_size)를 지정하여 배치 단위로 학습하도록 한다.
1
>>> loss_and_metrics = model.evaluate(val_inputs, val_targets, batch_size=128)
반환값으로 지정된 손실값과 평가지표를 담은 리스트가 생성된다.
1
2
>>> print(loss_and_metrics)
[0.29411643743515015, 0.5333333611488342]
예측
모델의 훈련과 검증이 완료되면 실전에서 새로운 데이터에 대한 예측을 진행한다.
데이터셋에 포함된 모든 데이터에 대한 예측을 한 번에 실행할 수 있으며
두 가지 방식이 존재한다.
모델 적용
모델을 마치 함수처럼 이용한다.
1
predictions = model(new_inputs)
내부적으론 앞서 설명한 __call()__ 메서드가 실행된다.
따라서 call() 메서드를 사용하는 포워드 패스가 실행되어
예측값이 계산된다.
하지만 이 방식은 입력 데이터셋 전체를 대상으로 한 번에 계산하기에
데이터셋이 너무 크면 계산이 너무 오래 걸리거나 메모리가 부족해질 수 있다.
따라서 배치를 활용하는 predict() 메서드를 활용할 것을 추천한다.
predict() 메서드
훈련된 모델의 predict() 메서드는 배치 크기를 지정하면
배치 단위로 예측값을 계산한다.
1
predictions = model.predict(new_inputs, batch_size=128)
모델 구성
- 입력 샘플이 벡터(1차원 어레이)로 주어지고 라벨이 스칼라(하나의 층)
- 밀집층 인
Dense층 - 은닉층의 활성화 함수:
relu,prelu,elu,tanh등이 많이 사용 - 이진 분류 모델의 최상위 출력층의 활성화 함수: 0 ~ 1사이의 함수
sigmoid함수 - 다중 클래스 분류 모델의 최상위 출력층의 활성화 함수
softmax함수
댓글남기기