
01 데이터베이스 시스템
01 데이터베이스와 데이터베이스 시스템
1. 데이터, 정보, 지식
- 데이터 : 관찰의 결과로 나타난 정량적 혹은 정성적인 실제 값 (8,848m)
- 정보 : 데이터에 의미를 부여한 것 (에베레스트 -> 8,848m)
- 지식 : 사물이나 현상에 대한 이해(다른 산과 비교 에베레스트는 가장 높은 산)
데이터베이스란?
- 조직에 필요한 정보를 얻기 위해 논리적으로 연관된 데이터를 모아 구조적으로 통합해 놓은 것
2. 일상생활의 데이터베이스

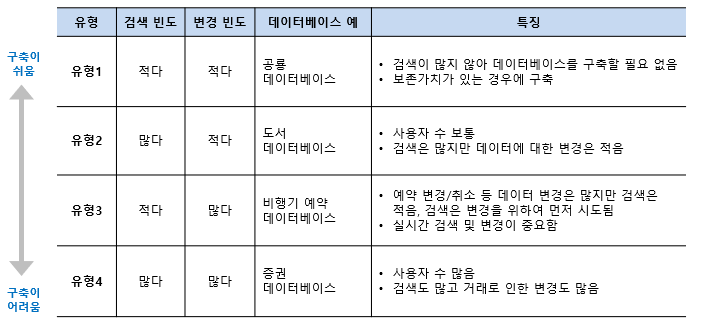
- 데이터베이스 시스템은 데이터의 검색과 변경 작업을 주로 수행
- 변경이란 시간에 따라 변하는 데이터 값을 데이터베이스에 반영하기 위해 수행하는 삽입, 삭제, 수정 등의 작업을 말함
3. 데이터베이스의 개념 및 특징
데이터베이스의 개념
- 통합된 데이터(integrated data)
- 데이터를 통합하는 개념으로, 각자 사용하던 데이터의 중복을 최소화하여 중복으로 인한 데이터 불일치 현상을 제거
- 저장된 데이터(stored data)
- 문서로 보관된 데이터가 아니라 디스크, 테이프 같은 컴퓨터 저장장치에 저장된 데이터를 의미
- 운영 데이터(operational data)
- 조직의 목적을 위해 사용되는 데이터, 즉 업무를 위한 검색을 할 목적으로 저장된 데이터
- 공용 데이터(shared data)
- 한 사람 또는 한 업무를 위해 사용되는 데이터가 아니라 공동으로 사용되는 데이터를 의미
데이터베이스의 특징
- 실시간 접근성(real time accessibility)
- 데이터베이스는 실시간으로 서비스된다. 사용자가 데이터를 요청하면 몇 시간이나 몇 일 뒤에 결과를 전송하는 것이 아니라 수 초 내에 결과를 서비스한다.
- 계속적인 변화(continuous change)
- 데이터베이스에 저장된 내용은 어느 한 순간의 상태를 나타내지만, 데이터 값은 시간에 따라 항상 바뀐다. 데이터베이스는 삽입, 삭제, 수정 등의 작업을 통하여 바뀐 데이터 값을 저장한다.
- 동시 공유(concurrent sharing)
- 데이터베이스는 서로 다른 업무 또는 여러 사용자에게 동시에 공유된다. 동시는 병행이라고도 하며, 데이터베이스에 접근하는 프로그램이 여러 개 있다는 의미이다.
- 내용에 따른 참조(reference by content)
- 데이터베이스에 저장된 데이터는 데이터의 물리적인 위치가 아니라 데이터 값에 따라 참조된다.
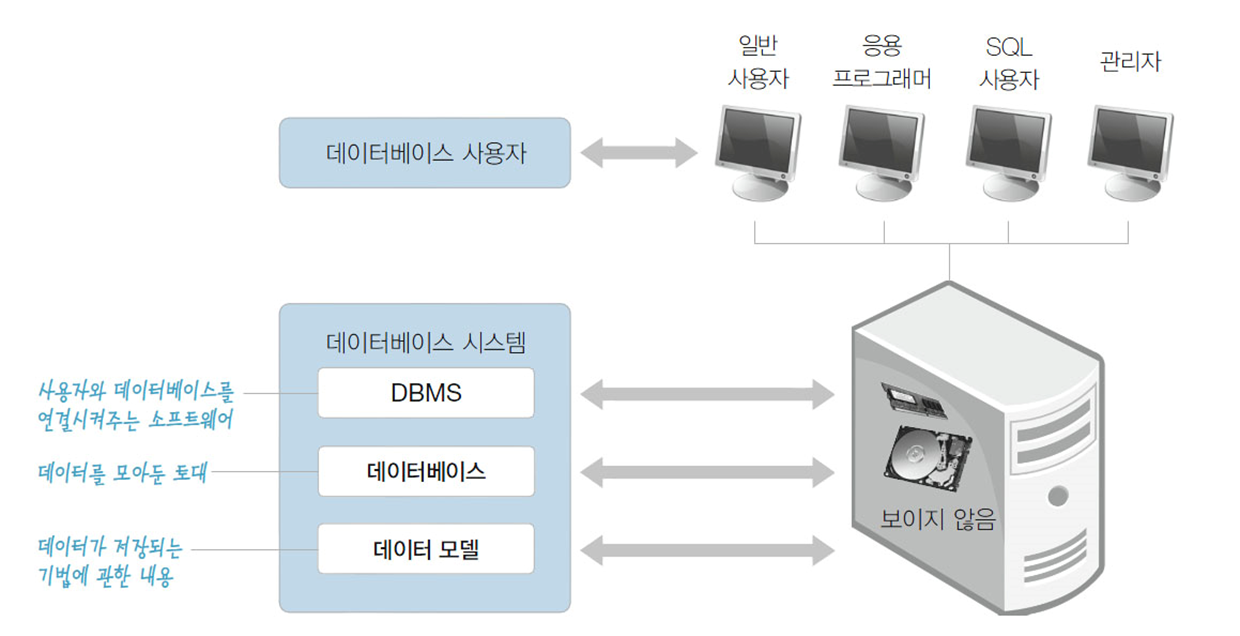
4. 데이터베이스 시스템의 구성
- DBMS: 사용자와 DB를 연결시켜주는 SW로 주기억장치에 상주
- 데이터 모델: 데이터가 저장되는 기법, 논리적인 개념으로 데이터가 저장되는 스타일
-
데이터베이스: 데이터를 모아둔 토대를 말하며, 물리적으로 컴퓨터 하드디스크에 저장
02 데이터베이스 시스템의 발전
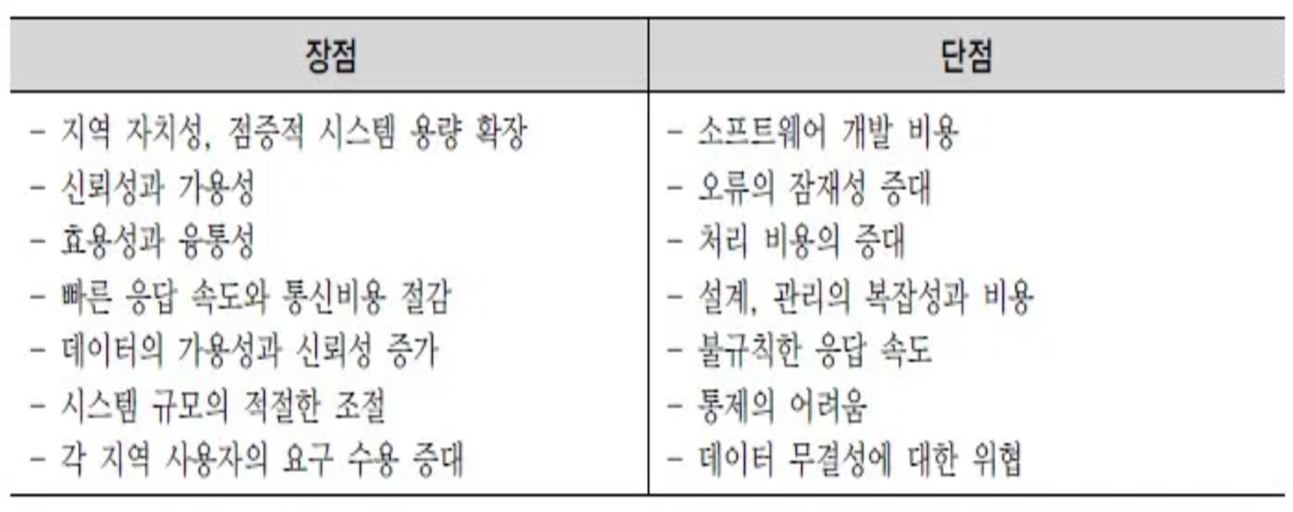
1. 데이터베이스 시스템의 예
- 마당서점의 시작 (1970년대 이전)
- 도서: 100권
- 고객: 근처 학교 학생, 지역 주민
- 업무: 회계 업무(계산기 사용), 장부 기록
- 고객 서비스: 사장이 안내
- 컴퓨터의 도입 (1980년대)
- 도서: 1,000권
- 고객: 근처 학교 학생, 지역 주민
- 업무: 회계 업무(계산기 사용), 파일 시스템
- 고객 서비스: 컴퓨터 검색
- 지점 개설 및 데이터베이스 구축 (1990년대)
- 도서: 10,000권
- 고객: 서울 지역 고객
- 업무: 회계 업무(컴퓨터 사용), 데이터베이스 시스템
- 고객 서비스: 클라이언트/서버 시스템으로 지점 연결해 검색
- 홈페이지 구축 (2000년대)
- 도서: 100,000권
- 고객: 국민
- 업무: 회계 업무(컴퓨터, 인터넷 사용), 웹 DB 시스템으로 지점 간 연계
- 고객 서비스: 인터넷으로 도서 검색 및 주문
- 인터넷 쇼핑몰 운영 (2010년대)
- 도서: 1,000,000권
- 고객: 국민
- 업무: 회계 업무(컴퓨터, 인터넷 사용), DB 서버 여러개 구축
- 고객 서비스: 인터넷 종합 쇼핑 서비스 제공

2. 정보 시스템의 발전
- 파일 시스템
- 데이터를 파일 단위로 파일 서버에 저장
- 각 컴퓨터는 LAN을 통해 파일 서버에 연결, 파일 서버에 저장된 데이터를 사용하기 위해 각 컴퓨터의 응용 프로그램에서 열기/닫기(open/close)를 요청
- 각 응용 프로그램이 독립적으로 파일을 다루기 때문에 데이터가 중복 저장될 가능성이 있음
- 동시에 파일을 다루기 때문에 데이터의 일관성이 훼손될 수 있음
- 데이터베이스 시스템
- DBMS를 도입하여 데이터를 통합 관리하는 시스템
- DBMS가 설치되어 데이터를 가진 쪽을 서버(server), 외부에서 데이터 요청하는 쪽을 클라이언트(client)라고 함
- DBMS 서버가 파일을 다루며 데이터의 일관성 유지, 복구, 동시 접근 제어 등의 기능을 수행
- 데이터의 중복을 줄이고 데이터를 표준화하며 무결성을 유지함
- 웹 데이터베이스 시스템
- 데이터베이스를 웹 브라우저에서 사용할 수 있도록 서비스하는 시스템
- 불특정 다수 고객을 상대로 하는 온라인 상거래나 공공 민원 서비스 등에 사용됨
- 분산 데이터베이스 시스템
- 데이터가 발생하는 곳이 여러 곳이면 각각 데이터베이스를 운영
- 여러 곳에 분산된 DBMS 서버를 연결하여 운영하는 시스템
- 대규모의 응용 시스템에 사용됨
- 분산데이터베이스의 정의
⇒ 빠른 네트워크 환경을 이용하여 데이터베이스를 여러 지역 여러 노드로위치시켜 사용성/성능 등을 극대화 시킨 데이터베이스
- 여러 곳으로 분산되어있는 데이터베이스를 하나의 가상 시스템으로 사용할 수 있도록 한 데이터베이스
- 논리적으로 동일한 시스템에 속하지만, 컴퓨터 네트워크를 통해 물리적으로 분산되어 있는 데이터들의 모임. 물리적 Site 분산, 논리적으로 사용자 통합·공유
- 데이터베이스 분산구성의 가치
- 핵심적인 가치는 바로 통합된 데이터베이스에서 제공할 수 없는 빠른 성능을 제공
- 네트워크 부하 및 트랜잭션 집중에 따른 성능 저하의 원인을 분산된 데이터베이스 환경을 구축하므로 빠른 성능을 제공하는 것이 가능
- 바로 이 점 때문에 분산 환경의 데이터베이스를 구축하게 되는 것이다.
- 분산 데이터베이스의 적용 기법
-
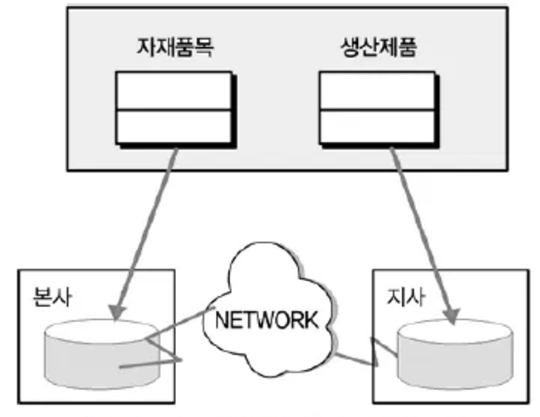
테이블 위치 분산
테이블 위치 분산은 테이블의 구조는 변하지 않는다. 또한 테이블이 다른 데이터베이스에 중복되어 생성되지도 않는다. 다만 설계된 테이블의 위치를 각각 다르게 위치시키는 것이다.
-
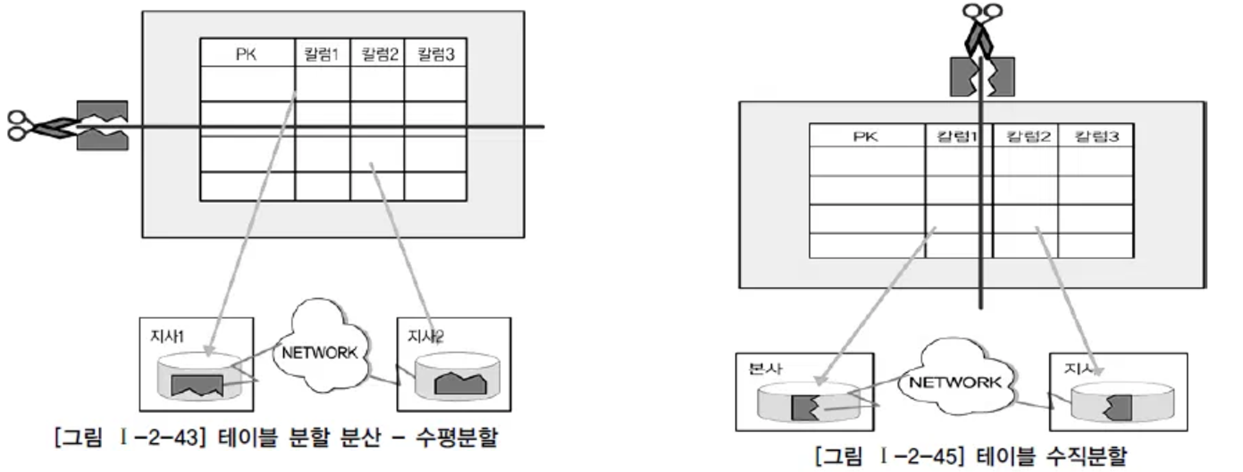
테이블 분할(Fragmentation) 분산
테이블 분할 분산은 단순히 위치만 다른 곳에 두는 것이 아니라 각각의 테이블을 쪼개어 분산하는 방법이다. 테이블을 분할하여 분산하는 방법은 테이블을 나누는 기준에 따라 두 가지로 구분된다
-
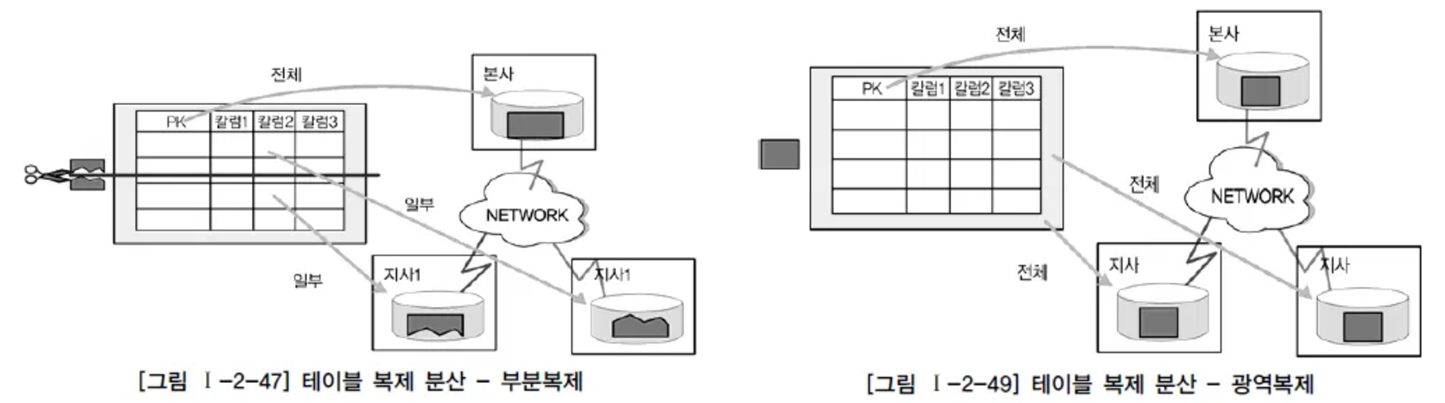
- 테이블 복제(Replication) 분산
-
테이블 복제(Replication) 분산은 동일한 테이블을 다른 지역이나 서버에서 동시에 생성하여 관리하는 유형이다. 마스터 데이터베이스에서 테이블의 일부의 내용만 다른 지역이나 서버에 위치시키는 부분복제(Segment Replication)가 있고 마스터 데이터베이스의 테이블의 내용을 각 지역이나 서버에 존재시키는 광역복제(Broadcast Replication)가 있다.
-
- 분산 데이터베이스의 장단점
- ⇒ 장점이 많기 때문에 분산 데이터베이스를 사용한다
정보 시스템의 발전(기업 규모)
03 파일 시스템과 DBMS
1. 데이터를 저장하는 방법
- 데이터를 프로그램 내부에 저장하는 방법
- 파일 시스템을 사용하는 방법
- DBMS를 사용하는 방법
- 데이터를 프로그램 내부에 저장하는 방법
[프로그램 1]
- C 언어의 구조체 BOOK을 먼저 선언하고 main( ) 프로그램에서 구조체 배열 변수 BOOKS[ ]에 데이터를 저장
- 도서 데이터는 프로그램 내 구조체 변수에 저장됨
- 문제점: 새로운 데이터가 생길 때마다 프로그램을 수정한 후 다시 컴파일해야 함 - 파일 시스템을 사용하는 방법
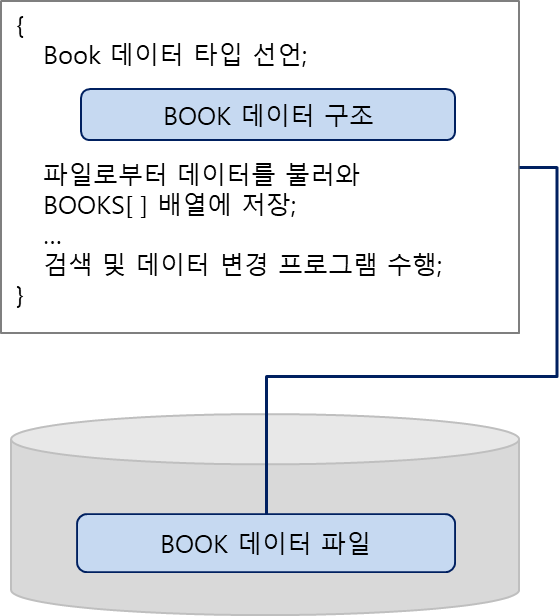
[프로그램 2]
- BOOK 데이터 구조를 먼저 선언하고 main( ) 프로그램에서 파일로부터 데이터를 불러와 구조체 배열 변수 BOOKS[ ]에 저장
- 새로운 데이터가 추가되어도 프로그램을 수정할 필요 없음
- 문제점 : 같은 파일을 두 개의 프로그램이 공유하는 것이 운영체제의 도움 없이 불가능 - DBMS를 사용하는 방법
[프로그램 3]
- 데이터 정의와 데이터 값을 DBMS가 관리
- DBMS는 데이터 정의, 데이터 변경 등의 작업을 할 수 있는 별도의 프로그램을 갖고 있음
- 프로그램에 데이터 정의나 데이터 값을 포함하지 않기 때문에 데이터 구조가 바뀌어도 다시 컴파일할 필요가 없음
2. 데이터의 저장 방법 비교
[프로그램 1] 구조

- 프로그램에 데이터 정의와 데이터 값을 모두 포함하는 방식
- 프로그램에 BOOK 데이터 구조를 정의하고 데이터 값도 직접 변수에 저장함
- 데이터 구조 혹은 데이터 값이 바뀌면 프로그램을 다시 컴파일해야 함
- 구조 + 데이터: 하나의 프로그램
- 구조가 바뀌면 재 컴파일 필요
- 데이터가 바뀌면 재 컴파일 필요
[프로그램 2] 구조
- 파일에 데이터 값, 프로그램에 데이터 정의를 포함하는 방식
- 프로그램에 BOOK 데이터 구조만 정의하고, 데이터 값은 book.dat라는 파일에 저장됨
- 데이터 값이 바뀌면 프로그램에 변경이 없지만, 데이터 구조가 바뀌면 프로그램을 다시 컴파일해야 함
- 구조 (프로그램) + 데이터 (파일): 분리
- 구조가 바뀌면 재 컴파일 필요
- 데이터가 바뀌면 재 컴파일 필요 X
[프로그램 3] 구조
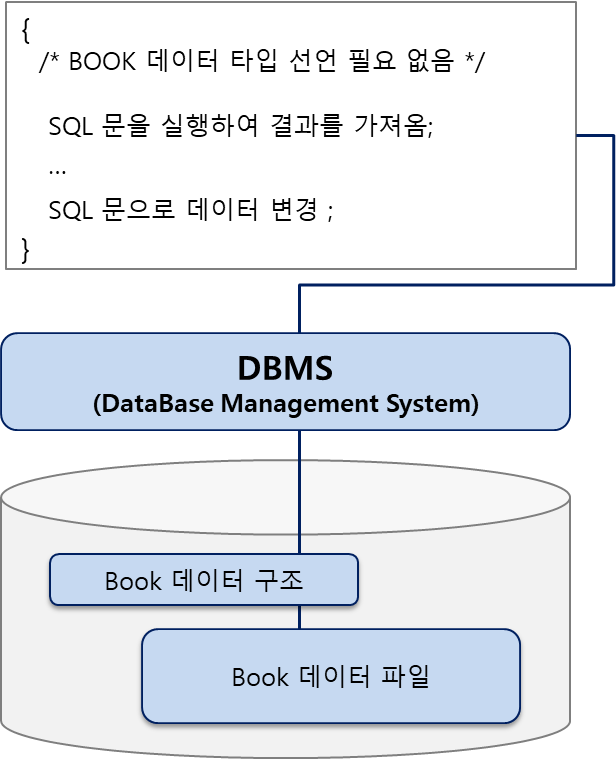
- DBMS가 데이터 정의와 데이터 값을 관리하는 방식
- BOOK 데이터 구조는 DBMS가 돤리하고, 데이터 값은 데이터베이스에 저장됨
- 데이터 구조가 바뀌거나 데이터 값이 바뀌어도 프로그램을 다시 컴파일할 필요 없음
- SQL 문으로 검색/삽입/삭제/수정
- 구조(DBMS) +데이터 (데이터베이스)
- 구조가 바뀌면 재 컴파일 필요 X
- 데이터가 바뀌면 재 컴파일 필요 X
3. 파일 시스템과 DBMS의 비교

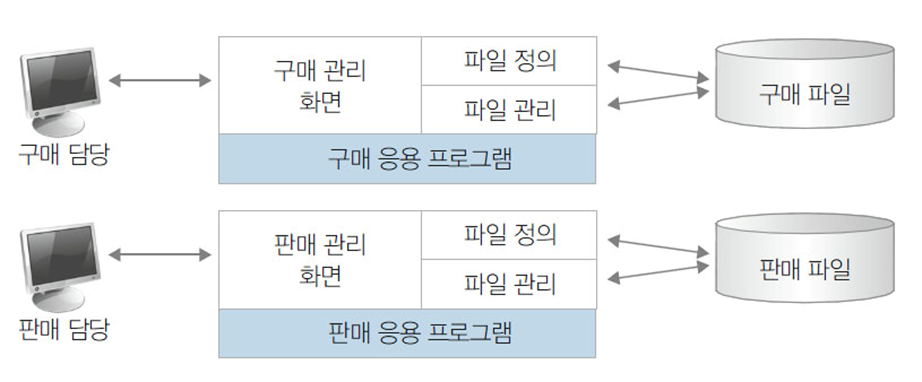
파일 시스템으로 구축된 구매 및 판매 응용 프로그램
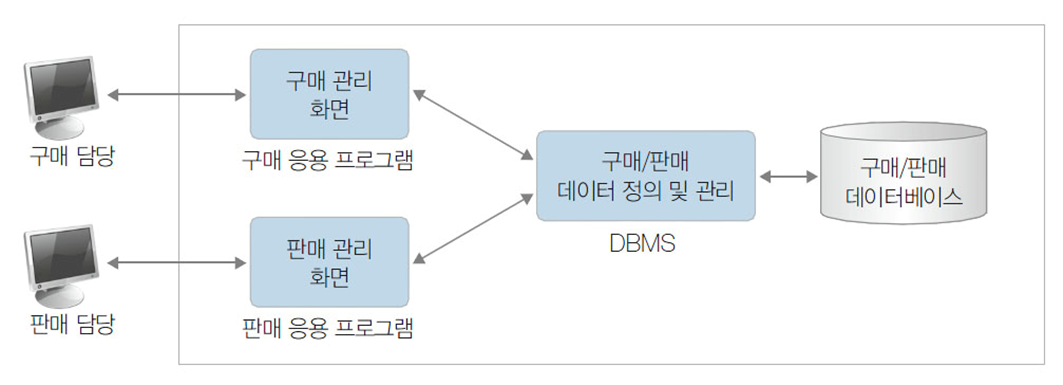
DBMS로 구축된 구매 및 판매 응용 프로그램
DBMS와 파일 시스템으로 구축된 프로그램의 차이점
파일시스템
- 데이터는 파일 형태로 저장.
- 데이터 구조화 및 관계 없음.
- 검색 및 쿼리 비효율적.
- 동시성 및 보안 관리 어려움.
- 데이터 백업 및 복원 수동 처리.
DBMS
- 데이터는 테이블 형태로 구조화.
- SQL을 통한 효율적인 검색 및 조작.
- 동시성 및 보안 관리 용이.
- 자동 데이터 백업 및 복원.
DBMS의 장점

04 데이터베이스 시스템의 구성
데이터베이스 시스템의 구성
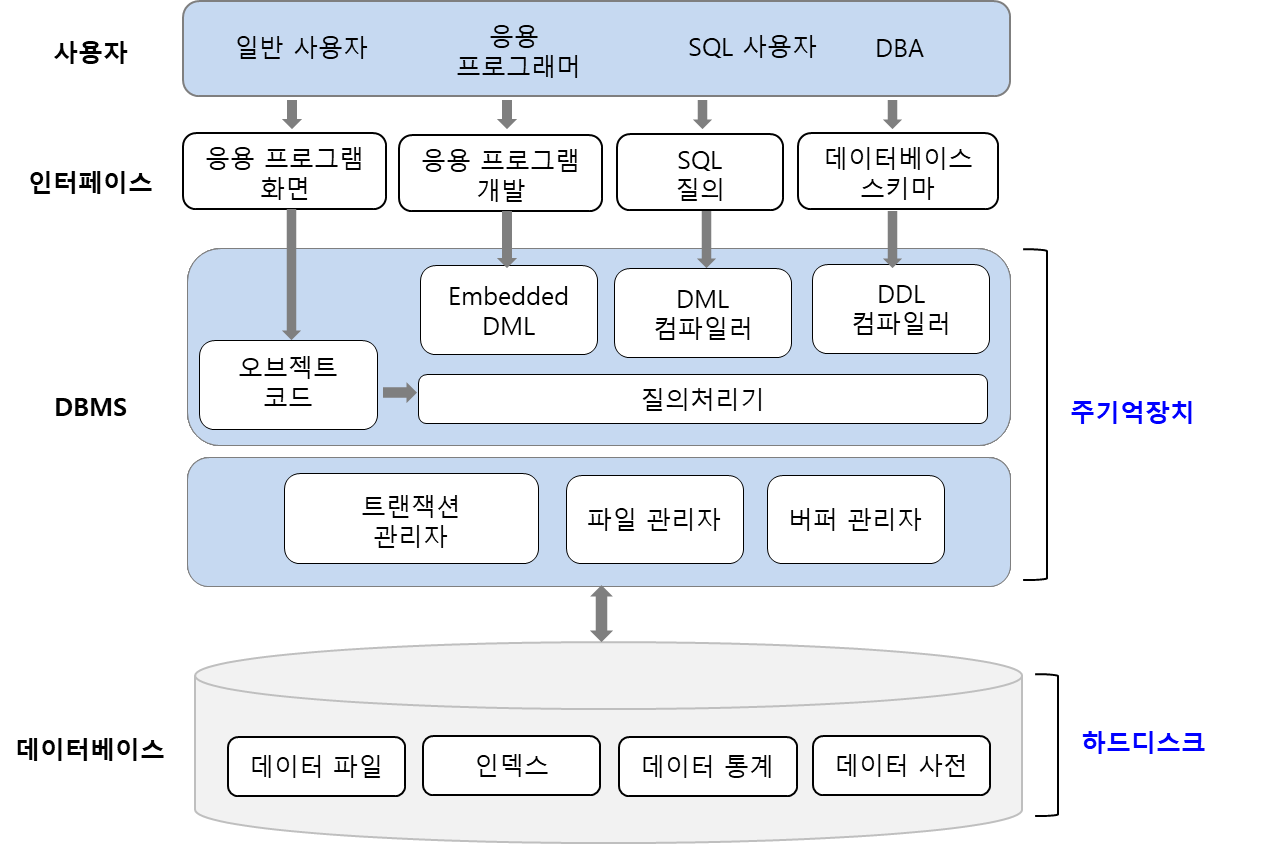
1, 데이터베이스 언어
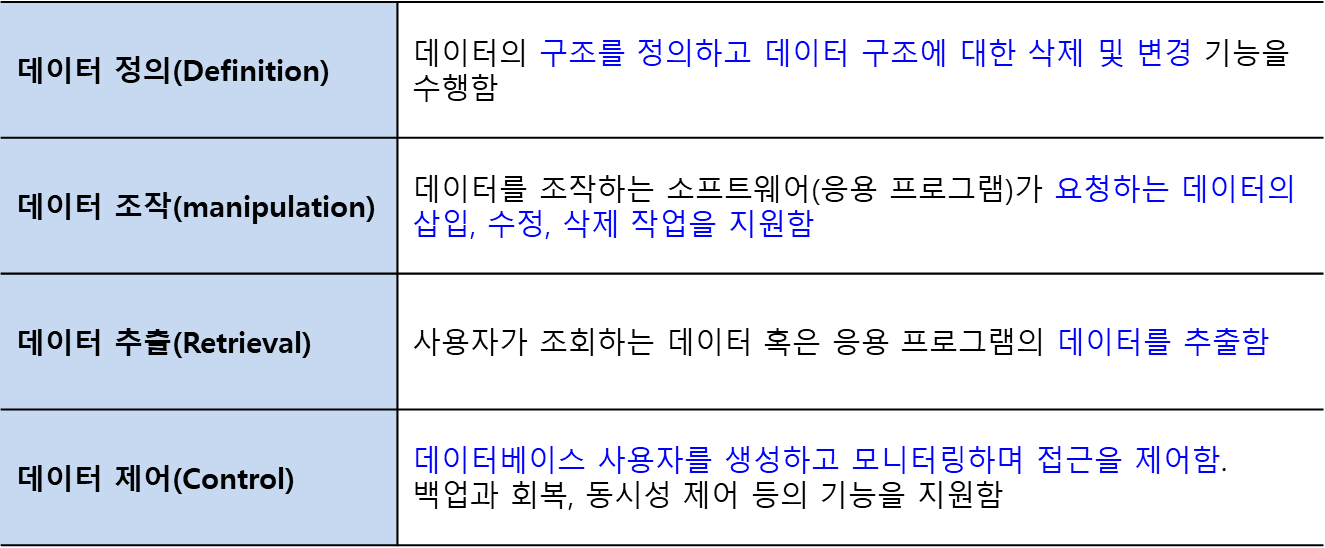
- SQL
- 데이터 정의어(DDL, Data Definition Language)
DBMS에 저장된 테이블 구조를 정의
CREATE: 새로운 데이터베이스 객체를 생성 (예: 테이블, 인덱스, 뷰 등).ALTER: 기존 데이터베이스 객체를 수정DROP: 데이터베이스 객체를 삭제
- 데이터 조작어(DML, Data Manipulation Language)
데이터를 검색, 삽입, 추가, 수정, 삭제
SELECT: 데이터를 조회하고 검색INSERT: 새로운 데이터를 데이터베이스에 추가UPDATE: 기존 데이터를 수정DELETE: 데이터를 삭제
- 데이터 제어어(DCL, Data Control Language)
데이터 사용 권한을 관리
(해당 내용은 다루지 않음)
GRANT: 사용자에게 특정 권한을 부여REVOKE: 사용자로부터 권한을 회수
- 데이터 정의어(DDL, Data Definition Language)
DBMS에 저장된 테이블 구조를 정의
- 아래 예시를 통해 DML을 다뤄보자.
-
Book 테이블
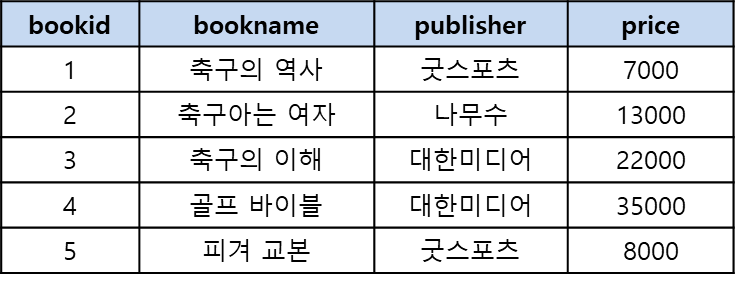
-
-
DML 예시: Book 테이블에서 모든 도서 이름과 출판사를 검색하라.
1 2
SELECT bookname, publisher FROM Book;
-
출력 결과
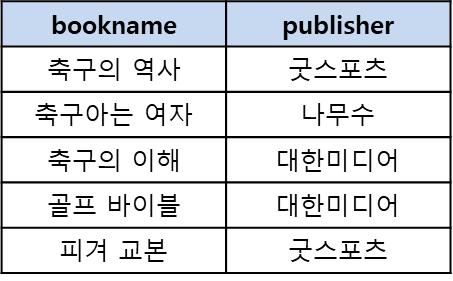
-
-
DML 예시: Book 테이블에서 가격이 10,000원 이상인 도서이름과 출판사를 검색하라.
1 2 3
SELECT bookname, publisher FROM Book where price >= 10000;
-
출력 결과
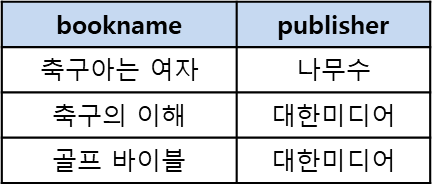
-
2. 데이터베이스 사용자
- 일반 사용자
- 은행의 창구 혹은 관공서의 민원 접수처 등에서 데이터를 다루는 업무를 하는 사람
- 프로그래머가 개발한 프로그램을 이용하여 데이터베이스에 접근 일반인
- 응용 프로그래머
- 일반 사용자가 사용할 수 있도록 프로그램을 만드는 사람
- 자바, C, JSP 등 프로그래밍 언어와 SQL을 사용하여 일반 사용자를 위한 사용자 인터페이스와 데이터를 관리하는 응용 로직을 개발
- 데이터베이스 프로그래머라고 말하기도 한다
- SQL 사용자
- SQL을 사용하여 업무를 처리하는 IT 부서의 담당자
- 응용 프로그램으로 구현되어 있지 않은 업무를 SQL을 사용하여 처리
- 주로 데이터 검색, 데이터 구조변경, 데이터에 관한 통계처리 등 데이터를 모니터링하는 업무
- 데이터베이스 관리자(DBA, Database Administrator)
- 데이터베이스 운영 조직의 데이터베이스 시스템을 총괄하는 사람
- 데이터 설계, 구현, 유지보수의 전 과정을 담당
- 데이터베이스 사용자 통제, 보안, 성능 모니터링, 데이터 전체 파악 및 관리, 데이터 이동 및 복사 등 제반 업무를 함
- DB 전문 지식
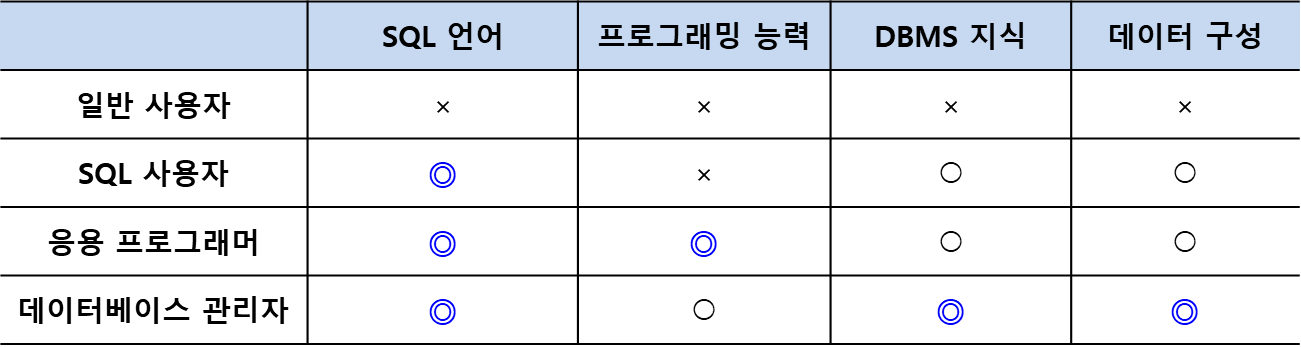
- 논외) DB 국제공인 및 국가공인 자격증
- 국제 자격증
DB의 80%가 오라클 사용, 오라클회사에서 주관하는 자격증.
- OCA Oracle Certified Associate
- OCP Oracle Certified Professional
- OCM Oracle Certified Master
- 국가공인 자격증
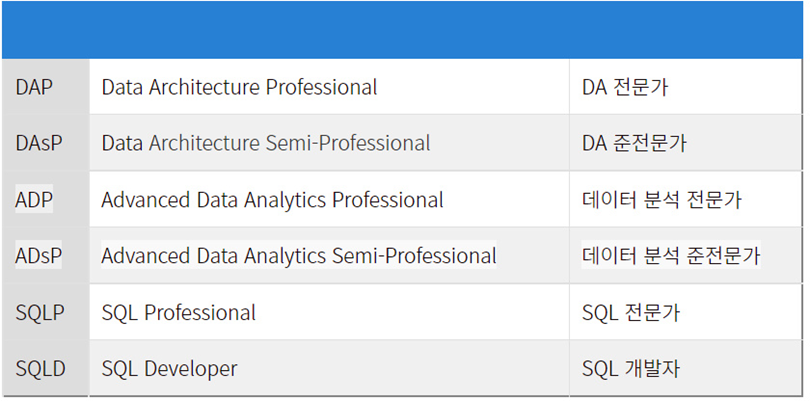
- 데이터 아키텍쳐(Data Architecture) - DAP , DAsP
- 데이터 분석 (Data Analytics) - ADP , ADsP
- SQL 관련 - SQLP, SQLD
- 국제 자격증
DB의 80%가 오라클 사용, 오라클회사에서 주관하는 자격증.
3. DBMS
4. 데이터 모델
데이터 모델의 그림의 출처: https://2srin.tistory.com/105
-
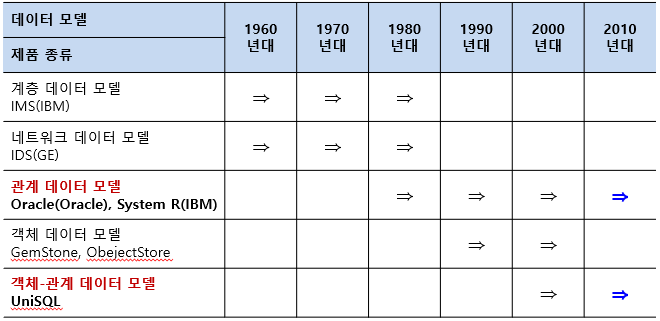
계층 데이터 모델(hierarchical data model)
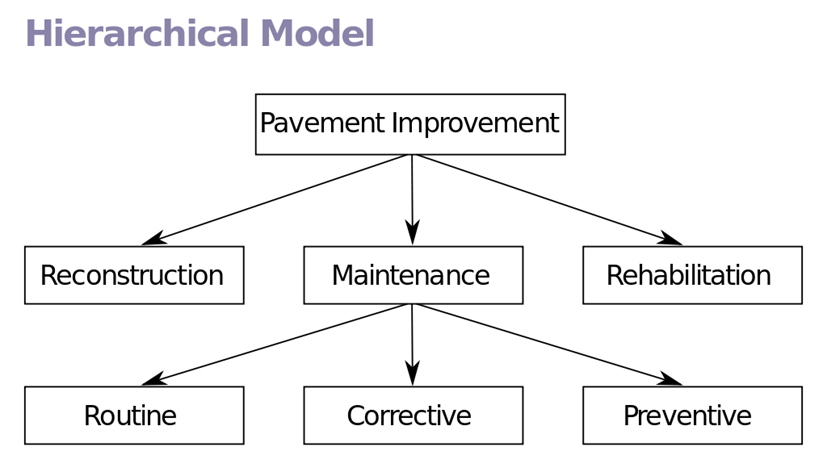
- 트리 형태의 계층적인 데이터 모델
- 1:N의 대응 관계만 존재
- 개체들 간에는 Cycle이 허용되지 않음
- 관계형 모델에서의 Entity를 계층형에선 Segment라 부름
- 파일 시스템을 생각하면 이해하기 쉽다.
- 폴더 안에 하위 폴더 안에 파일이 있는 형태
- 대표적인 DBMS는 IBM의 IMS가 있다.
- 단점
- 부모 레코드를 거치지 않고는 자식 레코드에 접근 불가능
- 상위 레코드 삭제시 연쇄 삭제(Triggered Delete)가 발생 출처: https://raisonde.tistory.com/entry/
-
네트워크 데이터 모델(network data model)
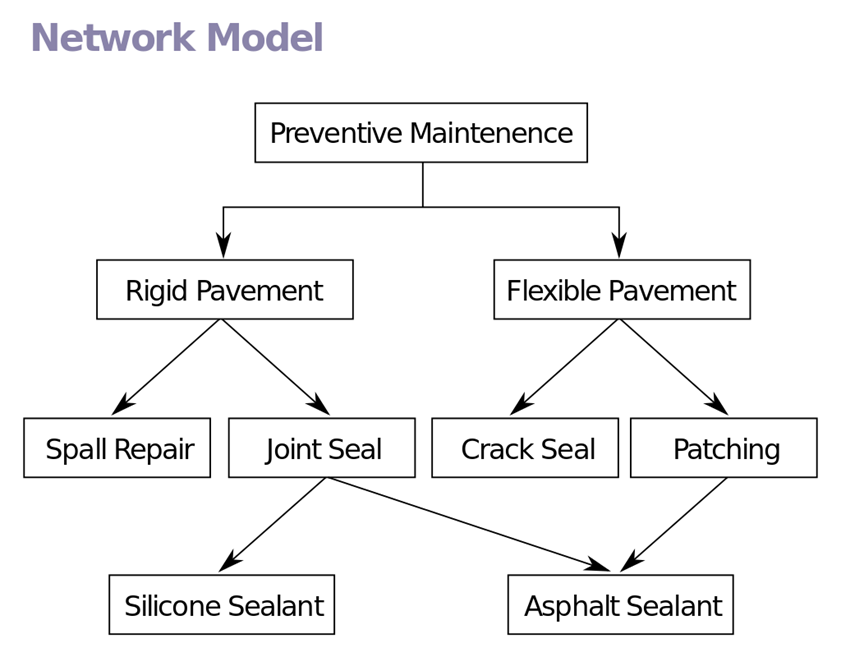
- 계층형의 단점을 좀 더 보완한 데이터 모델
- 상하위 레코드 사이에서 N:N구조를 허용
- 하위에서 상위로의 이동이 자유로우며 여러 상위 계층으로의 이동도 자유로움
- CODASYL DBTG모델이라고 불리기도 함
- 여기선 상하위 관계를 Owner, Member라고 표현
- 대표적인 DBMS는 DBTG, EDBS, TOTAL등…
- 단점
- 구조가 복잡하고 구현하기가 어려움 출처: https://raisonde.tistory.com/entry/
-
객체 데이터 모델(object data model)
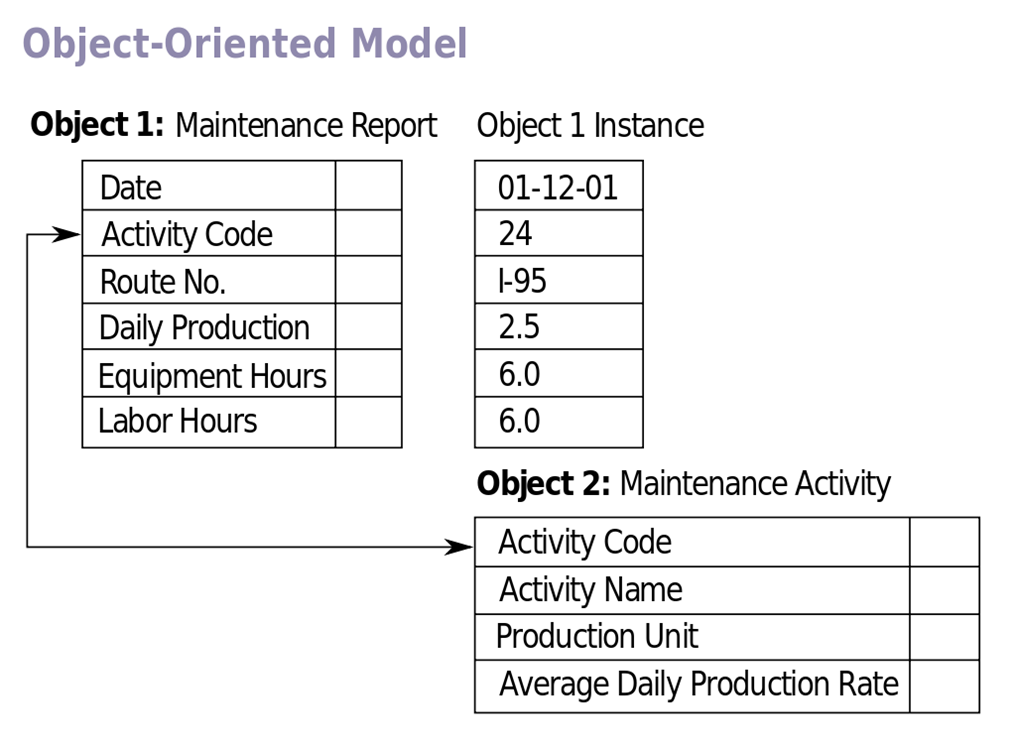
- 93년 객체지향DBMS(OODBMS)의 표준이 확립되면서 프로그래밍의 패러다임이 ‘절차적 프로그래밍’ 방식에서 ‘객체지향 프로그래밍’ 방식으로 전환되고 있었음
- 문제점
- 기존 2차원 형태의 테이블(table) 설계가 익숙한데, 굳이 자료 구조를 변경해야 할 이유가 없음
- 관계형 데이터베이스가 이론적인 면에서 더욱 단순하고, 유연성이 높다.
- SQL 쿼리를 쓸 수 없어서 불편함
- 검색 성능이 느리고, 대규모 트랜잭션 처리 성능이 떨어짐
- 대형 기관에 검증된 사례가 없다. 출처 : http://www.comworld.co.kr
-
관계 데이터 모델(relational data model : RDB) 가장 많이 사용됨
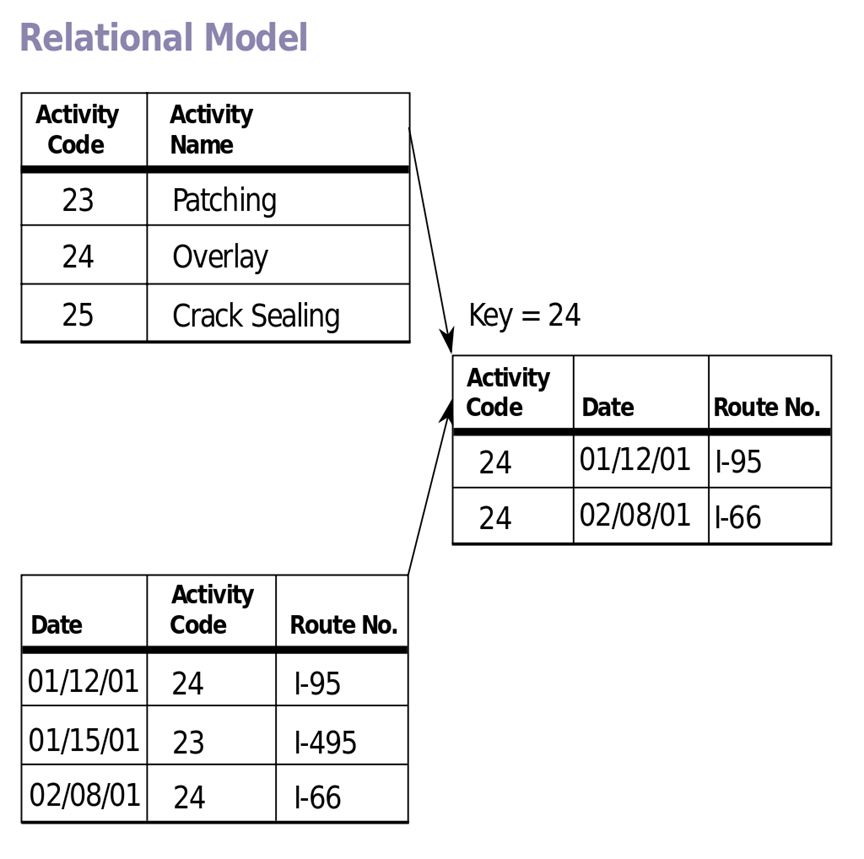
- 계층형, 네트워크형의 단점을 보완한 현재 가장 이상적인 모델
- 우리가 흔히 보는 Table(표)들로 구성되고 표의 칼럼간 관계가 정의되는 구조의 DB가 관계형 데이터 모델
- 대표적인 DBMS로 오라클, MySQL, MsSQL, SQLite 등… 우리가 아는 거의 모든 데이터 베이스들이 여기 속함
- 요즘 MongoDB, MariaDB같은게 다 관계형 DB다
- 거의 표준에 가까우므로 DBMS간 변환이 용이
- 단점
- 보기는 편한데 구현이 어려움
- 많은 연산에 대해 계층형/네트워크형보다 성능이 떨어지는 경우가 많음
-
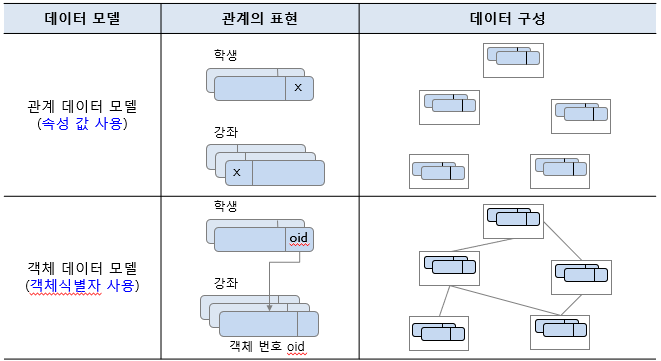
포인터 사용: 계층 데이터 모델, 네트워크 데이터 모델
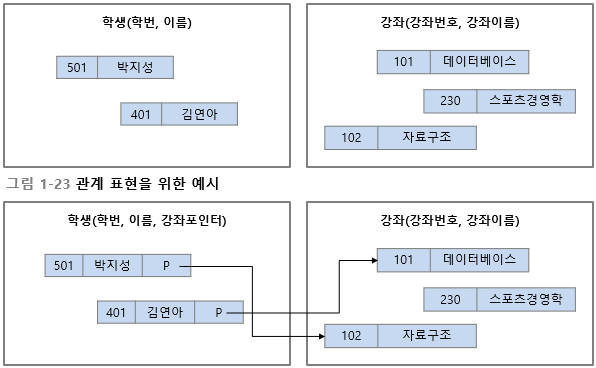
-
속성 값 사용: 관계 데이터 모델
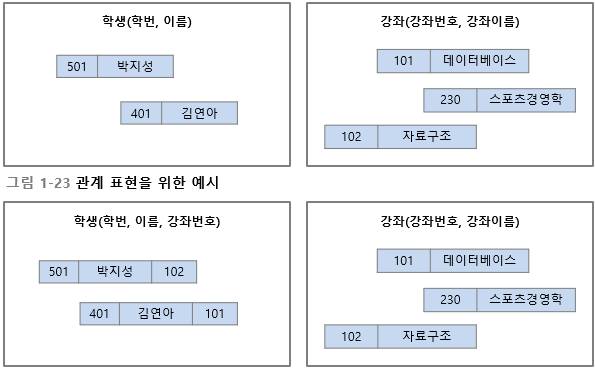
-
객체식별자 사용: 객체 데이터 모델
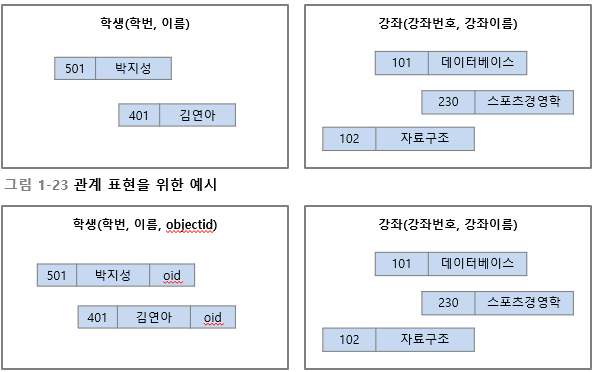
-
데이터 모델과 각 모델에서 관계의 표현 방법
-
데이터 모델의 역사
-
객체-관계 데이터 모델(object-relational data model : ORDB)
5. 데이터베이스의 개념적 구조
-
3단계 데이터베이스 구조
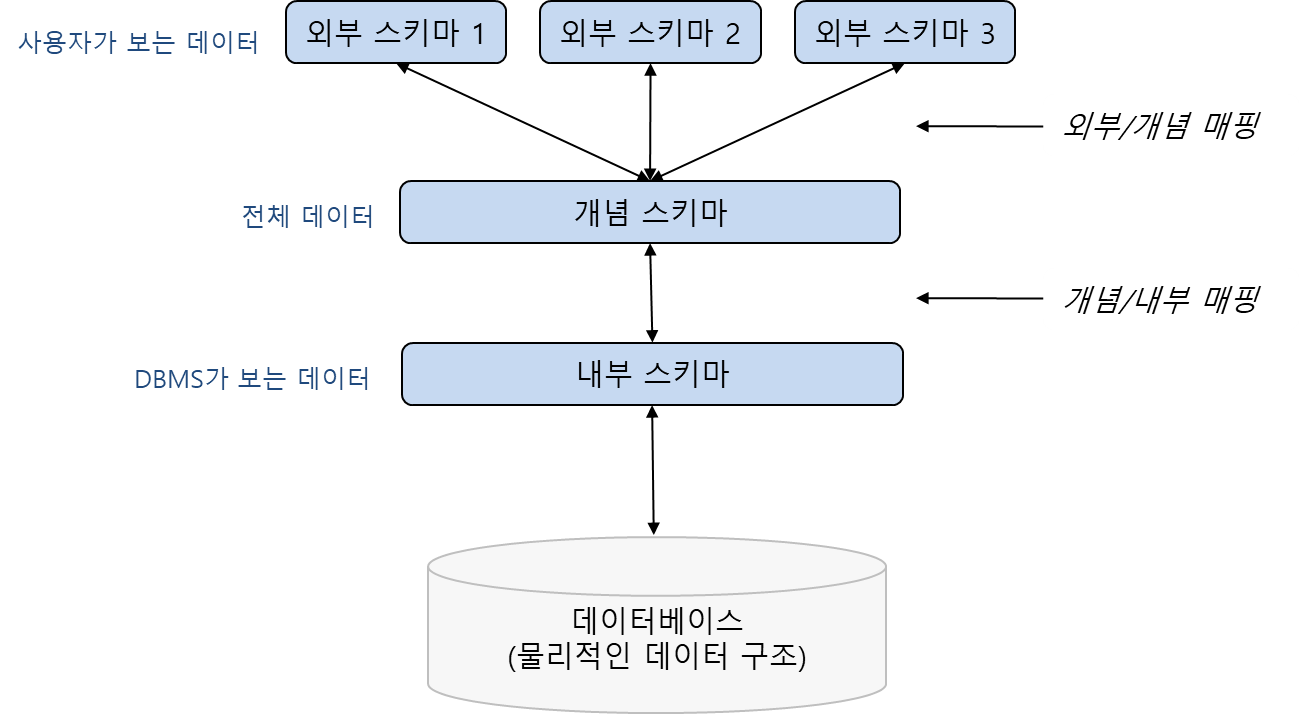
- 외부 단계
- 일반 사용자나 응용 프로그래머가 접근하는 계층으로 전체 데이터베이스 중에서 하나의 논리적인 부분을 의미
- 여러 개의 외부 스키마(external schema)가 있을 수 있음
- 서브 스키마(sub schema)라고도 하며, 뷰(view)의 개념임
- 개념 단계
- 전체 데이터베이스의 정의를 의미
- 통합 조직별로 하나만 존재하며 DBA가 관리함
- 하나의 데이터베이스에는 하나의 개념 스키마(conceptual schema)가 있음
- 내부 스키마
- 물리적 저장 장치에 데이터베이스가 실제로 저장되는 방법의 표현
- 내부 스키마(intenal schema)는 하나
- 인덱스, 데이터 레코드의 배치 방법, 데이터 압축 등에 관한 사항이 포함됨
- 외부/개념 매핑
- 사용자의 외부 스키마와 개념 스키마 간의 매핑(사상)
- 외부 스키마의 데이터가 개념 스키마의 어느 부분에 해당되는지 대응시킴
- 개념/내부 매핑
- 개념 스키마의 데이터가 내부 스키마의 물리적 장치 어디에 어떤 방법으로 저장되는지 대응시킴
- 외부 단계
- 데이터베이스 구조의 예: 수강신청 데이터베이스 구조
-
외부 스키마1
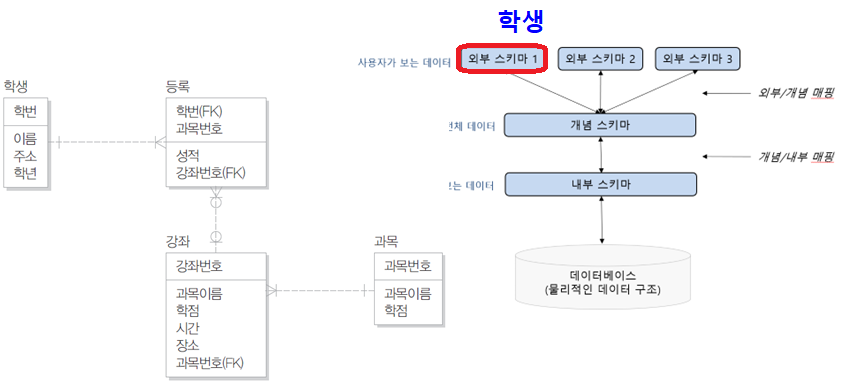
-
외부 스키마2
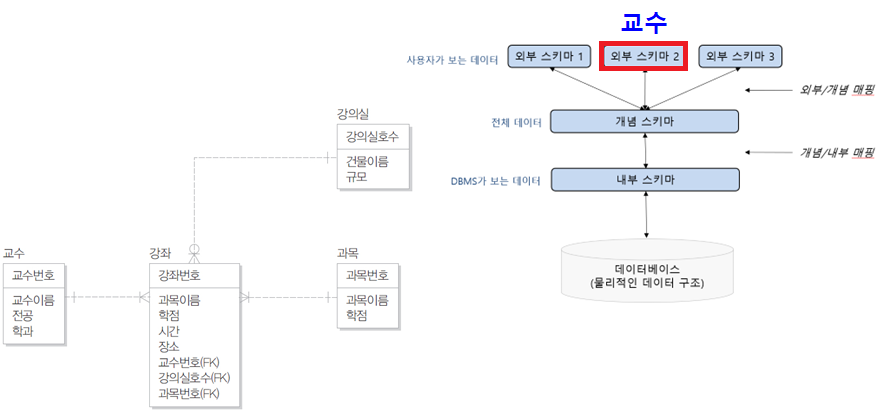
-
개념 스키마
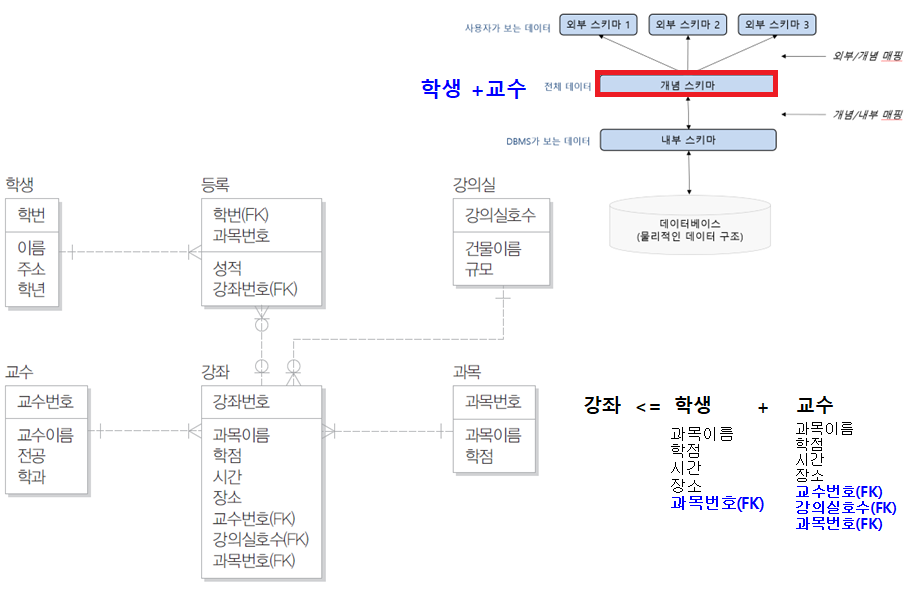
-
내부 스키마
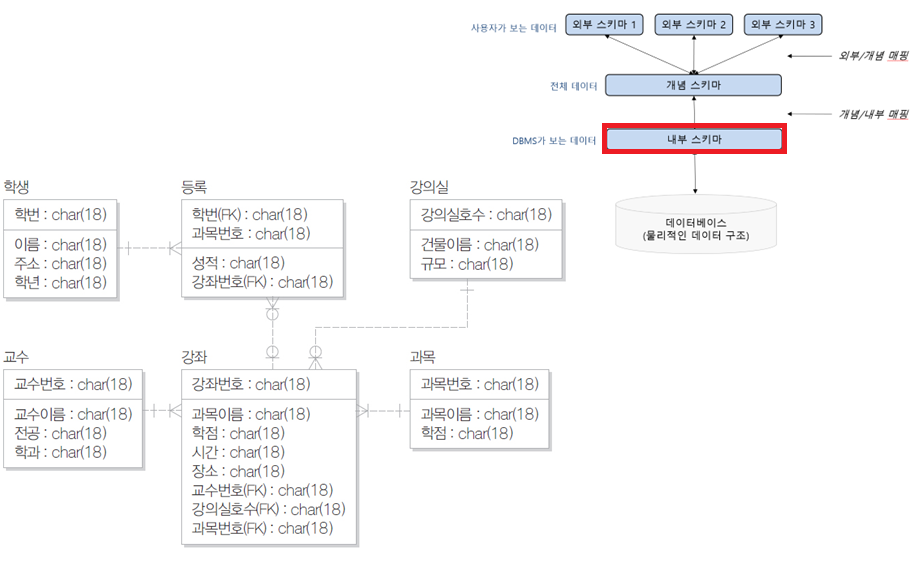
-
수강신청 데이터베이스의 3단계 구조
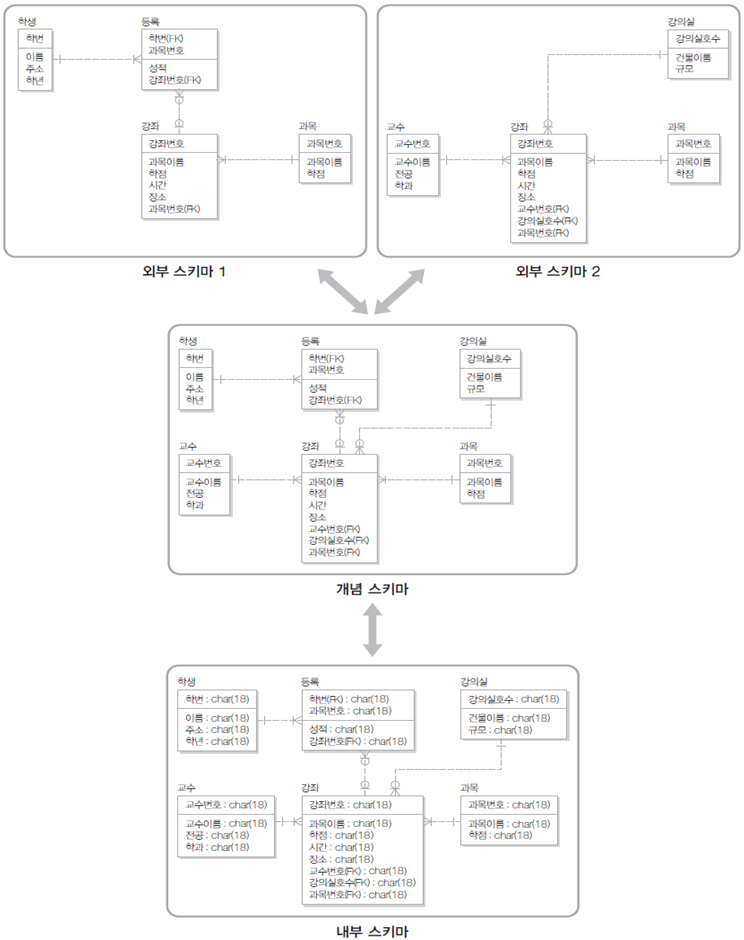
- 실제로는 외부 스키마가 이보다 더 많으나 표현하기 쉽게 2개만 나타냈다.
-
- 데이터 독립성
- 논리적 데이터 독립성(logical data independence)
- 외부 단계(외부 스키마)와 개념 단계(개념 스키마) 사이의 독립성
- 개념 스키마가 변경되어도 외부 스키마에는 영향을 미치지 않도록 지원
- 논리적 구조가 변경되어도 응용 프로그램에는 영향이 없도록 하는 개념
- 개념 스키마의 테이블을 생성하거나 변경하여도 외부 스키마가 직접 다루는 테이블이 아니면 영향이 없음
- 물리적 데이터 독립성(physical data independence)
- 개념 단계(개념 스키마)와 내부 단계(내부 스키마) 사이의 독립성
- 저장장치 구조 변경과 같이 내부 스키마가 변경되어도 개념 스키마에 영향을 미치지 않도록 지원
- 성능 개선을 위하여 물리적 저장 장치를 재구성할 경우 개념 스키마나 응용 프로그램 같은 외부 스키마에 영향이 없음
- 물리적 독립성은 논리적 독립성보다 구현하기 쉬움
- 논리적 데이터 독립성(logical data independence)
댓글남기기